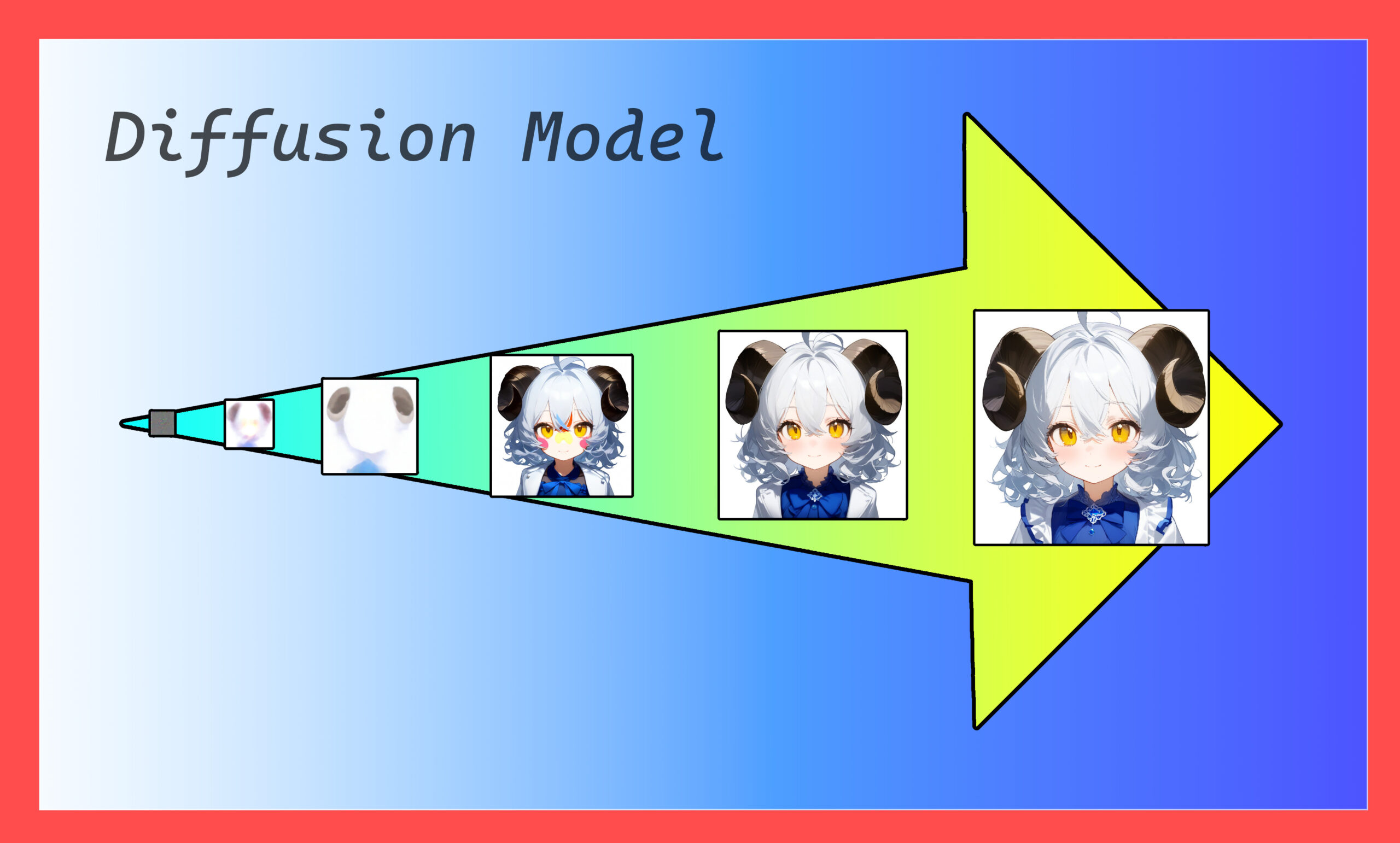
記事の概要
この記事では、潜在拡散モデルを用いた画像生成AIの仕組みについて詳しく解説します。特に、Stable Diffusion v1系で使用されるU-Netを用いたCNNベースの拡散モデルに焦点を当てています。Stable Diffusionはディープラーニング技術を活用し、潜在拡散モデルによって効率的で高品質な画像生成を実現しています。この手法は、従来の方法と比べて計算コストを抑えながら高いパフォーマンスを達成しています。また、最新のCNNベースのモデルであるSDXLについても触れます。
潜在拡散モデルは、低次元の潜在空間で拡散過程や逆拡散過程を行うことで、計算コストを削減しつつ生成品質を向上させる技術です。これにより、高品質な画像生成が可能となり、テキストからの画像生成を始めとした多様なタスクに柔軟に対応できます。
「生成AIの基本的な知識および画像生成AIの方法」のセクションでは、生成AIとは何か、そしてどのように画像生成が行われるのかといった基本的な知識を解説します。生成AIは、データから新しいデータを生成する技術で、画像生成AIはその一例です。「拡散モデルの仕組み」のセクションでは、画像生成の中心的な技術である「拡散モデル」について詳しく説明します。拡散過程と逆拡散過程という二つの主要なステップを通して、どのようにノイズから画像が生成されるのかを理解していただきます。「画像生成AIに使用されている技術」のセクションでは、画像生成に使われている各種技術を紹介します。このセクションでは、CLIP、U-Net、VAE、そして潜在拡散モデル(LDM)について詳しく説明し、これらの技術がどのように連携して画像生成を実現するのかを解説します。「潜在拡散モデルにおける画像生成の流れ」のセクションでは、潜在拡散モデルにおける画像生成のプロセスを、学習段階と生成段階の二つに分けて解説します。この手法を用いることで、効率的に高品質な画像を生成する仕組みについて理解していただける内容です。「SDXL(Stable Diffusion XL)」のセクションでは、最新の画像生成AIモデルであるSDXLについて説明します。このモデルが従来のモデルとどのように異なるのか、またどのような特徴を持っているのかを紹介します。
U-Netを使用した高品質な画像生成は、標準的な拡散モデルの手法として評価されてきました。しかし、最近の技術では、U-Netに代わり拡散トランスフォーマー(Diffusion Transformer)を利用するアプローチが注目されています。例えば、SoraやStable Diffusion 3、FLUX 1.0などの最新のモデルでは、拡散トランスフォーマーを用いています。
拡散トランスフォーマーは、トランスフォーマーの強力な表現力を活かし、より精度の高い学習を可能にし、画像の細部まで精密に生成できます。また、拡散トランスフォーマーは優れたスケーリング特性を持ち、柔軟に複数の生成タスクに適応可能です。画像生成技術は進化を続けており、トランスフォーマーの利用により、生成の精度と多様性がさらに向上しています。
しかし、本記事ではあえてU-Netを用いたCNNベースの潜在拡散モデルに焦点を当てています。これは、現在がまだ拡散トランスフォーマーへの移行期であり、U-Netを用いたCNNベースの拡散モデルの価値を理解する機会は今しかないと思っているからです。SDXLまでのU-Netを用いたStable Diffusionは、多くの場面で優れた結果を示しており、そのシンプルさと効果の高さが注目されています。また、U-Netを用いた拡散モデルは、その構造の理解が容易であり、画像生成の基礎を学ぶための優れた教材でもあります。 この記事を通じて、画像生成AIの基礎から最新技術までの理解が深まり、生成AIの未来に向けた興味がさらに広がることを願っています。
生成AIの基本的な知識および画像生成AIの方法
生成AIとは
イ 生成 AI の開発の概略
生成 AI の開発は、機械学習のうちの深層学習と言われる手法等により、大量かつ多様なデータを情報解析し、データから読み取れる多数のパターンやルール、傾向等を学習させ、指示に対して、的確な出力を予測できるように調整を行うことで進められる。
また、生成 AI を含む AI においては、その目的に応じて言語、画像等のデータを学習に用いる必要があり、これらの学習に用いるデータの質及び量が、その性能の決定に大きな影響 を与えると言われている。
ウ 生成 AI が生成物を生成する機序の概略
生成 AI では、入力された指示を情報解析し得られた結果と、その生成 AI が学習したパターンやルール、傾向等に基づき、生成物を生成することとなる。この際の生成については、本小委員会の審議においてもヒアリング等を通じて確認したように、例えばテキストの生成においては、ある単語に続く単語の出現確率を計算することを繰り返すことで生成が行われているものであり、通常、学習データの切り貼りによって生成を行うものではないとされる。
生成AIは、機械学習の一手法である深層学習を活用して開発されます。この手法では、大量かつ多様なデータを用いてパターンやルール、傾向を学習し、入力された指示に基づいて新たな出力を生成します。学習にはテキストや画像といったさまざまなデータを用いており、その質と量が生成AIの性能に大きく影響を与えます。
生成AIの開発プロセスには、いくつかの重要なステップがあります。まず、大量のデータセットを準備し、それを深層学習モデルによって学習させます。この学習によって、データに内在するパターンや特徴の統計データが特徴量(ベクトル)としてモデルに組み込まれます。次に、モデルに入力された指示に基づいて、学習した情報をもとに新たな出力を生成します。この際、AIは単にデータを模倣するだけでなく、統計的に蓄積されたパターンを元に創造的な出力を行うよう調整されています。例えば、画像生成AIでは、膨大な画像データから学んだ視覚的な特徴を利用し、与えられたテーマに沿った新しい画像を生成することが可能です。
生成AIの生成のプロセスは、入力された指示に基づいて情報を解析し、学習したパターンやルールに従って生成物を作成します。例えば、テキスト生成では、ある単語に続く単語の出現確率を計算することで文章が構成されます。このように、生成AIは学習データをそのまま切り貼りして使うのではなく、統計的な推測を通じて新しい生成物を作り出すのが特徴です。
また、画像生成の場合には、生成AIがノイズから徐々に画像を作り出す「拡散モデル」と呼ばれる技術を使用することもあります。この技術は、まずランダムなノイズを生成し、それをAIが少しずつ除去して最終的な画像に近づけていくという手順です。この「拡散モデル」に関しては次の項目で扱います。
この過程において生成AIは、学習データから得た特徴を元に、新しい画像やテキストを生成することができ、既存のコンテンツをただコピーするのではなく、あくまでそれを基にして新しいものを創り出しています。このため、生成AIが生み出す生成物は、新しい創作物として扱うことができ、既存のデータの切り貼りではありません。
これらの点を踏まえ、生成AIの開発とその応用は、単なる技術的な進歩だけでなく、社会的な影響も考慮しながら進められています。生成AIは今後も進化を続け、より多くの分野で私たちの生活や仕事に影響を与えることが期待されます。
画像生成AIの生成方法とは
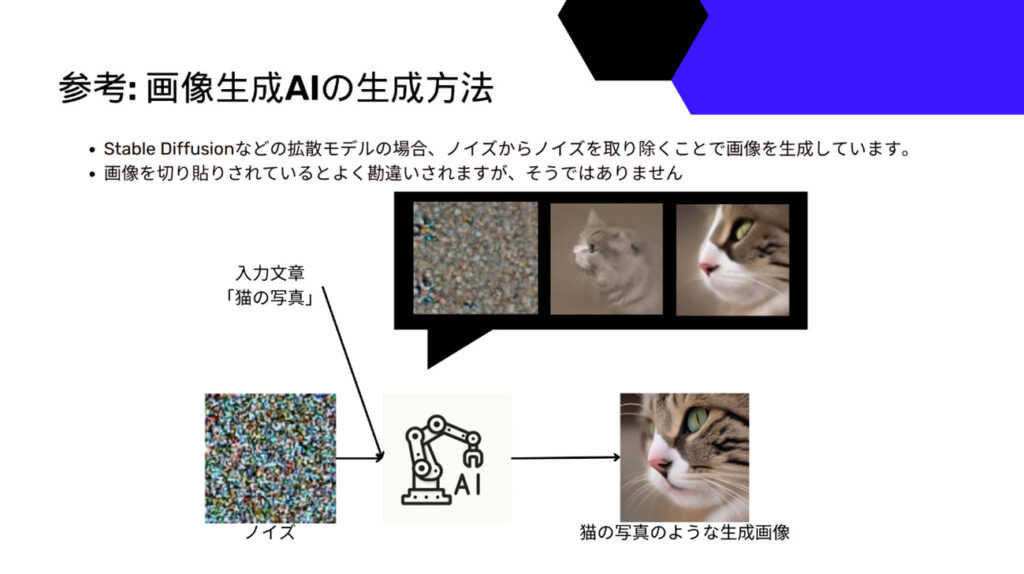
出典:内閣府知的財産戦略推進事務局,AI時代の知的財産権検討会(第2回),資料3, AI Picasso株式会社 提出資料, 2023年10⽉18⽇ AI Picasso株式 代 冨平喜,10頁
この資料では、画像生成AI、特にStable Diffusionのような拡散モデルを用いた生成の流れが説明されています。拡散モデルは、ノイズを徐々に取り除くことによって画像を生成する仕組みを持っています。
拡散モデルによる画像生成プロセス
- ノイズからのスタート
最初の段階では、全体がノイズである画像を生成します。このノイズの画像は、最終的に生成される画像の基盤となります。
- 入力文章の利用
例えば、「猫の写真」といった入力文章がモデルに与えられると、AIはその文章から生成したい画像の概念を理解します。このテキスト情報を基に、AIはどのような要素を画像に含めるべきかを推測していきます。
- ノイズを徐々に取り除く
拡散モデルでは、ノイズを少しずつ取り除いていく過程で画像を生成します。このプロセスは「逆拡散過程」とも呼ばれ、徐々にノイズを減らしながら、ターゲットとなる画像(この場合は猫の写真)の具体的な特徴を浮かび上がらせていきます。生成された中間段階の画像は最初ぼんやりとしていますが、プロセスが進むにつれて徐々に猫の形や特徴が鮮明になります。
- 最終的な生成画像
最終的に、ノイズが完全に取り除かれ、「猫の写真」のようなリアルな画像が得られます。この過程では、ノイズの除去に加えて入力テキストに基づく特徴が反映され、猫の特徴が明確に描写された画像が生成されます。
拡散モデルによる画像生成は「切り貼り」ではない
画像生成AIは、既存の画像を「切り貼り」しているわけではなく、数学統計的なモデルを使って新たに画像を構築しています。このプロセスの特徴は以下の通りです。
- ノイズからの生成: AIは純粋なノイズから画像を作り出すため、全てのピクセルがAIの計算によって新たに生成されています。既存の画像をコピーして使用することはありません。このため、生成される画像はまさに「新たに作られた」ものといえます。
- テキスト情報を基にした生成: 入力されたテキストは生成する画像の内容に直接影響を与えます。AIは学習した膨大なデータから「猫」や「写真」の概念を統計を取り特徴量として理解し、それを基に新しい画像を生成します。例えば、「かわいい猫」といったテキストを与えれば、AIは「かわいさ」の特徴を学習によって得られた特徴量から引き出し、画像に反映させます。
- クリエイティブなプロセス: このように、拡散モデルを使った画像生成は、単なる「画像の切り貼り」ではなく、ノイズの除去と特徴の強化を繰り返すことで新たな画像を生成する創造的なプロセスです。そのため、最終的に生成された画像は新しいものであり、与えられたテキストに基づいて作り上げられたものです。
これらの特徴により、拡散モデルは単なるデータの再利用ではなく、真に新しい画像を生成する能力を持っています。
拡散モデルの仕組み
画像データの基本
画像データはピクセルの集合体で、1ピクセルにはRGB(Red, Green, Blue)の256階調の組み合わせがあります。例えば、512ピクセル×512ピクセルの画像を完全にランダムに生成しようとすると、512ピクセル×512ピクセル×256階調の約4兆分の1の確率で特定の画像を得られることになります。しかし、この方法ではほとんどの場合ノイズしか得られません。そのため、この画像から望む絵に近づけるための手法が必要です。それが「拡散モデル」を用いた生成技術です。
画像生成の難しさは、ただランダムにピクセルを配置するだけでは意味のある画像が得られない点にあります。各ピクセルの色の組み合わせは、周囲のピクセルと連携して全体の構図や意味を成します。拡散モデルは、このような高度な相関を取り入れながら、ノイズから情報を引き出すことにより、最終的な画像を生成する技術です。この技術では、ノイズから段階的に情報を再構築し、意味のあるビジュアルを作り出すことが可能です。
拡散モデルとは?
拡散モデルは、最初にノイズから始まり、少しずつノイズを除去していくことで、最終的に明確な画像を生成する技術です。この方法は「逆拡散過程」とも呼ばれ、機械学習の一種である深層学習技術を活用しています。このプロセスにより、ノイズから徐々に情報を抽出し、与えられた指示(プロンプト)に基づいて画像を生成します。
この手法の強みは、最初は無秩序なノイズであっても、AIが繰り返しノイズを取り除くことで徐々に意味のある画像を構築できる点にあります。これにより、拡散モデルは高い生成能力を持ち、非常に精細でリアルな画像を出力することができます。また、プロンプトを活用することで、特定のテーマやスタイルに沿った画像を生成することが可能になり、ユーザーの要求に柔軟に応じることができます。
Denoising Diffusion Probabilistic Models(ノイズ除去拡散確率モデル)
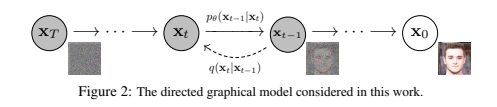
出典:Jonathan Ho, Ajay Jain, Pieter Abbeel,” Denoising Diffusion Probabilistic Models”,2P,Figure2
ノイズ除去拡散確率モデル:Denoising Diffusion Probabilistic Models (DDPM)では、拡散過程(Forward Process)と逆拡散過程(Reverse Process)という2つの主要なステップを用いて画像を生成します。拡散モデルでは、まず画像に段階的にノイズを追加してデータを乱雑にし、その後、そのノイズを少しずつ取り除きながら元のデータに近づけていくという学習の手順を踏んでいます。
- 拡散過程 (Forward Process)
拡散過程では、元の画像データに対して段階的にノイズを追加していきます。この作業を繰り返すことで、元の情報は徐々に消え、最終的には完全にノイズだけで構成されたデータになります。このプロセスを通じて、AIはノイズを加えられたデータの特性を学習します。
- 逆拡散過程 (Reverse Process)
次に、完全にノイズ化されたデータからノイズを少しずつ取り除きながら、元の画像を再構築していきます。この過程では、AIが条件付けに基づいてノイズ除去を行い、各ステップでわずかにノイズを減らしながら画像を再構築します。最初は全くのノイズであっても、各ステップで少しずつノイズを除去し、最終的には意味のある画像にたどり着くことができます。これによってノイズ画像から新たな画像を生成する方法を学習します
図の説明:
図では、まず左端のノイズ化された画像から始まり、逆拡散過程を通じてノイズが少しずつ除去され、中間段階の画像を経て、最終的にクリアな画像が生成される流れが示されています。この一連のステップにおいて、ノイズ除去のたびにAIが学習したパターンに基づいて画像が生成される仕組みになっています。 拡散モデルの強みは、ランダムなノイズからでもAIがノイズを取り除くことで高品質な画像を生成できる点にあります
画像生成AIに使用されている技術
CLIP
CLIP(Contrastive Language-Image Pretraining)は、画像生成AIにおいて重要な役割を果たしており、特に拡散モデルの分野で利用されることが増えています。CLIPは、テキストと画像のペアを学習し、画像の内容とその説明を結びつける強力なエンコーダーを構築します。この機能により、画像生成プロセスでプロンプトとして与えられるテキストを適切に理解し、それに基づいて生成される画像の内容を決定します。
CLIPは、画像エンコーダーとテキストエンコーダーという2つのモデルを用いて、画像とテキストのペアの類似度を高めるように訓練されます。インターネットから収集した4億組の画像とテキストのペアを使って学習を行います。このプロセスは、テキストと画像が意味的に対応しているかを予測することを目的としており、結果としてCLIPは画像とテキストの関連性を高い精度で判断することが可能です。そのため、拡散モデルにおいてもプロンプトに基づいた具体的な画像を生成する際、CLIPの持つ強力な表現学習能力が活かされています。
拡散モデルでは、ノイズから画像を生成する際にプロンプトに基づいた指針が必要です。この指針を提供するのがCLIPの役割です。テキストエンコーダーによって入力されたプロンプトを理解し、その内容に基づいて画像の特徴を調整します。例えば「猫の写真」というプロンプトが与えられた場合、CLIPはそのテキスト情報を元に猫の特徴を反映した画像を生成するように、拡散プロセスに指示を与えます。
この仕組みにより、CLIPは従来の画像生成モデルと比較して、ユーザーの意図を反映した画像生成が可能になります。プロンプトが持つ意味情報を高精度で理解し、それを基にして画像のノイズを段階的に除去しながら、最終的にはユーザーが望む内容の画像を生成します。このようにして、CLIPは拡散モデルにおける画像生成の精度と柔軟性を大幅に向上させています。
Contrastive Pre-training(コントラスト学習による事前学習)
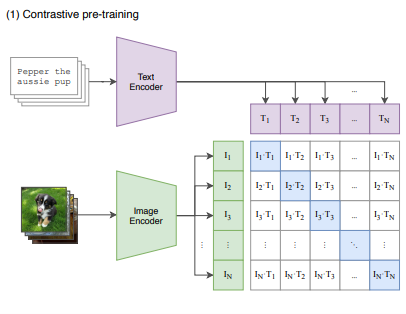
CLIPは、テキストと画像のペアを学習し、入力されたテキスト(プロンプト)の特徴と画像の特徴を結びつけます。これにより、ユーザーが入力したテキストの意味を正確に捉え、そのテキストに基づいた最適な画像を生成することが可能になります。
CLIPには、テキストエンコーダーと画像エンコーダーという2つのエンコーダーがあり、それぞれのデータを埋め込みベクトルに変換します。具体的には、画像データは画像エンコーダーを通して特徴量が抽出され、埋め込みベクトル(I1, I2, I3…)として表現されます。同様に、テキストデータはテキストエンコーダーを通じて埋め込みベクトル(T1, T2, T3…)に変換されます。この埋め込みベクトルを用いて、テキストと画像が一致するかどうかのコサイン類似度を計算し、コントラスト学習によって正しいペアの類似度を最大化し、誤ったペアの類似度を最小化します。
この学習プロセスを通じて、CLIPはテキストと画像の間の意味的な関連性を深く理解します。生成段階では、与えられたプロンプトに基づいて最も適した画像の特徴を拡散モデルに提供し、ノイズから望ましい画像を生成するようサポートします。CLIPの役割は、プロンプトに合致した画像を生成するように、拡散モデルの各ステップにおいて埋め込みベクトルを用いてガイドラインを提供することです。これにより、生成される画像がプロンプトの意味に最も近いものになるよう調整されます。
例えば、「猫」というプロンプトが与えられた場合、CLIPはそのテキストの意味を理解し、猫の特徴を持つ画像を生成するように拡散プロセスに指示を与えます。また、「猫」というプロンプトに対しては、猫の画像とはコサイン類似度が非常に高くなりますが、猫と似た特徴を持つ「サーバル」の画像とも類似度が高くなる可能性があります。一方で、猫の特徴から離れた「犬」の画像とのコサイン類似度は低く、「自動車」の画像とは非常に低くなります。このように、CLIPはプロンプトに基づいて適切な画像を選択し、拡散モデルがその情報に基づいて画像を生成できるようにします。
CLIPはこのように、プロンプトと画像生成を強力にリンクさせることで、ユーザーの意図に沿った画像生成が可能となり、拡散モデルの生成精度と柔軟性を大幅に向上させます。特に、CLIPは学習したテキストと画像のペアを用いて生成プロセスを支援するため、ユーザーが入力するプロンプトに対して、より適切なビジュアルアウトプットを提供することが可能です。これにより、生成された画像はプロンプトの内容を的確に反映し、ユーザーの要求に応える高品質なビジュアル表現が実現されます。
U-Net
U-Netは、収縮パスと拡張パスから成る対称的なU字型アーキテクチャで、前者はコンテキストをキャプチャし、後者は高解像度のセグメンテーションを可能にします。
高解像度の特徴マップとアップサンプルされた出力を結合し、より正確なセグメンテーションを実現します。
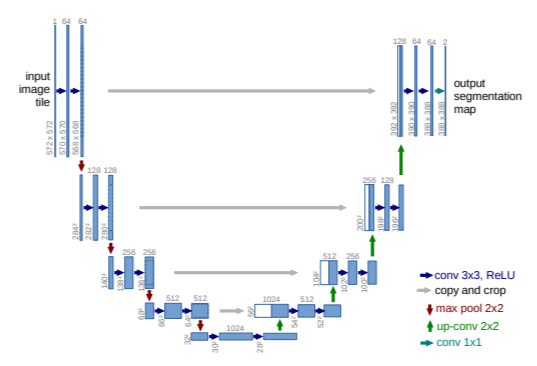
U-Netは、医療画像のセグメンテーションに特化した畳み込みニューラルネットワークであり、その特徴的なU字型構造により、少ない学習データでも高精度なセグメンテーションを実現します。このネットワークは、入力画像から各ピクセルごとにセグメンテーションマップを生成することができます。特に、収縮パスと拡張パスの対称的な構造により、画像全体のコンテキストを捉えながら細部の精度も確保することが可能です。
U-Netのアーキテクチャ
以下に、U-Netのアーキテクチャの各部分について詳しく説明します。
入力から出力までの全体的な流れ
U-Netは、左側の収縮パス(contracting path)と右側の拡張パス(expansive path)で構成されるU字型の構造を持っています。このネットワークは、入力画像タイルをセグメンテーションマップに変換するプロセスを表しています。
収縮パス(contracting path)
左側の部分が収縮パスです。これは典型的な畳み込みニューラルネットワークのアーキテクチャに従っています。
- 各段階で3×3の畳み込み(conv 3×3, ReLU)を適用し、その後にReLUを使用して活性化します。
- 次に、2×2のマックスプーリング(max pool 2×2)でストライド2を使用して、画像サイズを半分に縮小し、特徴の抽出と抽象化を進めます。
- 各ダウンサンプリングのステップで、特徴チャネルの数が倍増します。これにより、ネットワークはより多くの特徴を学習できます。
ボトルネック部分
中央の部分がボトルネックと呼ばれ、ここでは画像の特徴が最大限に縮小されます。この段階でのチャネル数は1024と多くなり、画像全体のコンテキストが集約されます。
拡張パス(expansive path)
右側の部分が拡張パスです。ここでは、収縮パスで得られた特徴を高解像度の出力に戻していきます。
- アップサンプリング(up-conv 2×2)を行い、画像の解像度を元に戻します。この操作は、ダウンサンプリングで失われた空間情報を取り戻す役割を果たします。
- 拡張パスの各ステップで、収縮パスから対応する特徴マップをコピーして結合(copy and crop)します。これにより、高解像度の特徴とコンテキスト情報を統合し、精度の高いセグメンテーションを実現します。
- 最後に、1×1の畳み込み(conv 1×1)で、各ピクセルをセグメンテーションクラスにマッピングします。
特徴チャネルと画像サイズ
図中の青いボックスは、各層での多チャネルの特徴マップを表しています。各ボックスの上にはチャネル数が記載されており、左下には各層での画像サイズが示されています。これにより、ネットワーク内の各層での処理を具体的に理解することができます。
U-Netの特徴
- 完全に畳み込みの構造:U-Netは全ての層が畳み込みで構成され、全結合層はありません。そのため、任意のサイズの入力画像を処理できる柔軟性があります。
- データ増強の活用:U-Netは、データが少ない状況でも効率的に学習できるように、データ増強(例えば、弾性変形)を強力に活用しています。
この構造により、U-Netは医療画像のセグメンテーションにおいて非常に高い精度を発揮し、例えば細胞や神経構造のセグメンテーションにおいて優れた結果を示しました。
VAE
Variational Autoencoder (VAE)はデータ生成のためのモデルです。VAEは、データの背後にある隠れたパターンを学習するために、確率的なエンコーダーとデコーダーを使うオートエンコーダーの一種です。ここでは、VAEについて簡単に説明します。
VAEは、観測データを再現するための隠れた変数(潜在変数)の分布を学習することを目的としています。VAEは次の2つの重要な部分から成り立っています
- エンコーダー:観測データから潜在変数の分布を予測します。この分布は通常、観測データに基づくガウス分布(平均と分散を使った正規分布)として表されます。
- デコーダー:エンコーダーで得られた潜在変数から観測データを再構成します。デコーダーは、潜在変数から観測データを生成するための確率的な関数です。
VAEを学習するには、データの背後にある潜在変数をモデル化するために、変分推論という手法を使います。具体的には、以下の手順で行います。
変分下限の最大化:VAEは、観測データの再現性を高めるために、対数尤度の下限(変分下限)を最大化します。この変分下限は以下の2つの項からなります。
- 再構成誤差:潜在変数から生成したデータと元の観測データの違いを測定します。この誤差が小さいほど、元のデータを正確に再現していることを意味します。
- KLダイバージェンス:潜在変数の近似分布と事前に設定した分布の違いを測ります。この項は、潜在変数の分布が事前分布に近づくようにするための制約です。
SGVB(Stochastic Gradient Variational Bayes)推定量:VAEの学習では、変分下限を効率的に最大化するために、SGVB推定量という手法を使います。これは確率的な勾配法で変分下限を最適化する方法で、リパラメータ化トリックを使って潜在変数を扱いやすくし、直接的に勾配を計算できるようにします。
VAEは、画像生成などに用いられています。例えば、MNISTという画像データセットでの実験では、VAEは潜在空間におけるデータの特徴的な表現を学び、それを使って新しい画像を生成できます。
このように、VAEはエンコーダーとデコーダーを組み合わせた構造を持ち、観測データの背後にある潜在構造を学習します。そのため、VAEはデータ生成やデータの表現を学ぶための強力なツールとなります。
Latent Diffusion Models
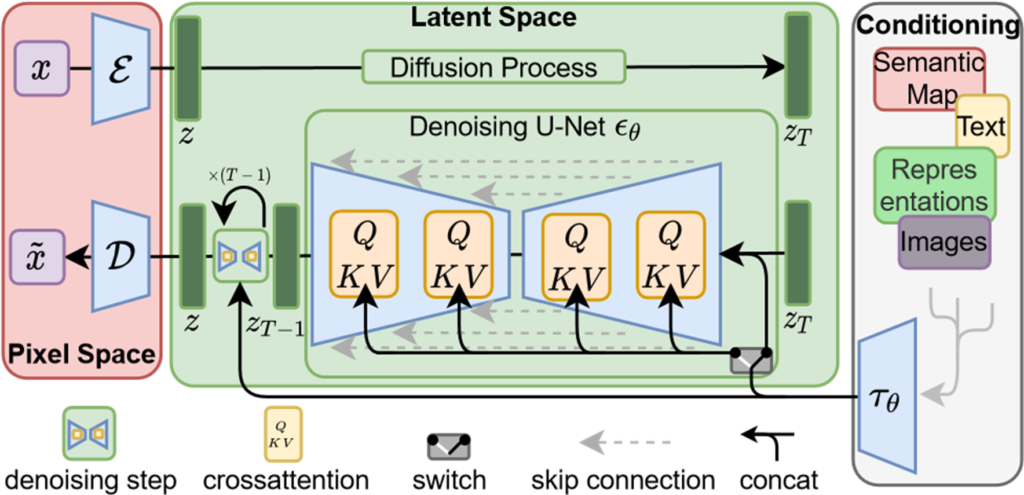
潜在拡散モデル(Latent Diffusion Model, LDM)は、オートエンコーダの潜在空間で拡散モデルを訓練することで、計算コストを大幅に削減しながら、高品質な画像生成を可能にする手法です。この方法は、ピクセル空間で直接モデルを訓練する従来の手法に比べて、効率的であり、計算資源の消費を抑えることができます。
潜在空間での訓練
まず、ピクセル空間の画像をオートエンコーダに入力し、画像を低次元の潜在表現に変換します。この潜在表現は、元の画像の特徴を保持しながらも計算を効率化するための低次元表現です。オートエンコーダは、エンコーダとデコーダの2つの部分から構成されており、エンコーダが画像を潜在表現に変換し、デコーダがその潜在表現を基に画像を再構築します。
潜在空間での拡散モデル
次に、この潜在空間において拡散モデルを学習します。拡散モデルでは、ノイズを徐々に加えていく過程(拡散プロセス)を通じて、データの潜在表現を効果的に学習します。最初に元の潜在変数に少しずつノイズを加え、最終的に完全なノイズに至るまで繰り返します。その後、このノイズの加わった状態から元の潜在変数を復元することを目標とします。
デノイジングと条件付け
ノイズを除去する過程(デノイジング)は、U-Netを用いて実現されます。U-Netは、画像の詳細と全体的な文脈情報をうまく統合しながらノイズを取り除きます。このデノイジングの過程では、内部の各ステップでクロスアテンション層を通じて条件付き入力(例:テキストやセマンティックマップ)を取り入れ、潜在表現を更新します。この条件付けにより、テキストやセマンティックマップといった外部情報を使って生成される画像を制御することが可能です。
最終的な再構築
ノイズが除去された潜在表現は、オートエンコーダのデコーダによってピクセル空間に再構築され、最終的に高品質な画像が生成されます。このプロセスにより、潜在空間での効率的な学習とピクセルベースの生成に匹敵する高精度な画像生成が可能となります。
このアプローチにより、LDMは計算コストを削減しつつ、テキストからの画像生成や画像の超解像、インペインティング(画像の一部を補完するタスク)など、さまざまなタスクにおいて優れた性能を発揮します。
潜在拡散モデルにおける画像生成の流れ
今までの知識を踏まえながら実際の潜在拡散モデルの流れを詳細に解説していきます。
学習段階
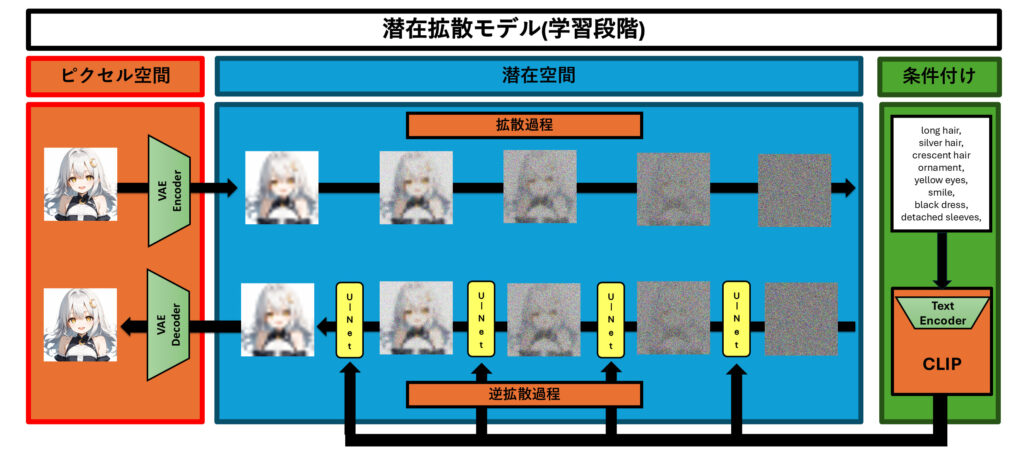
この画像は、潜在拡散モデル(Latent Diffusion Model, LDM)の学習プロセスを視覚的に示しています。以下、画像に基づいて潜在拡散モデルの学習段階について解説します。
ピクセル空間から潜在空間への変換
まず、左側のピクセル空間で表現される元の画像(例えばキャラクターの画像)を、VAE(変分オートエンコーダ)を使って潜在空間に変換します。この過程で、VAEのエンコーダーが画像の特徴を抽出し、それを低次元の潜在表現に変換します。この潜在空間は、元の画像の重要な情報を低次元へと変換した表現であり、モデルの計算効率を大幅に向上させるために使われます。
潜在空間での拡散過程
次に、潜在空間での拡散過程が行われます。この過程では、元の潜在変数に少しずつノイズを加えていき、最終的に完全にノイズだらけの状態にします。このとき、潜在変数に加わったノイズの影響で、画像は少しずつぼやけたものから完全にノイズに変わっていきます。画像に示されているように、潜在空間での各ステップでノイズが徐々に加えられていきます。
ノイズを加えるこの過程は、データをよりランダムにし、学習を通じてさまざまな変動に対応できるようにすることが目的です。最終的には、このノイズ化された状態から元の潜在変数を再構築することが学習のゴールです。
逆拡散過程とU-Netによるデノイジング
次に、ノイズが加えられた潜在表現を逆拡散過程を通じて元の状態に復元します。このデノイジングの過程は、U-Netを使って行われ、ノイズを取り除くことで、潜在空間の画像が徐々に元の形に戻っていきます。画像中の「U-Net」と書かれた黄色のボックスが、このデノイジングのプロセスを表しています。
条件付けによる生成制御
条件付けは、生成される画像の内容をコントロールするために使われます。右側の緑色の部分では、テキスト条件(例:「long hair, silver hair, smile」など)が示されています。これらのテキスト情報は、CLIPモデルのテキストエンコーダーを使って埋め込みベクトルに変換され、U-Netによるデノイジングの各ステップで使用されます。この方法によって、特定の特徴(例えば「黒いドレス」や「笑顔」など)を持つ画像を生成することが可能になります。
最終的な再構築
ノイズが取り除かれた潜在表現は、再びVAEのデコーダーによってピクセル空間に戻され、最終的に高品質な画像が再構築されます。この過程を通じて、元の特徴を維持しながら、条件付け情報を反映した画像を生成することができます。例えば、指定した髪の色や服装などを持つキャラクターの画像が得られます。
潜在拡散モデルの特徴
潜在拡散モデルの大きな特徴は、ピクセル空間で直接訓練するのではなく、低次元の潜在空間で訓練を行うことにより、計算コストを大幅に削減できる点です。また、条件付け情報を使って画像をコントロールすることで、より具体的な特徴を持つ画像の学習ができるという強みもあります。
変分オートエンコーダー(VAE)の働き
変分オートエンコーダー(VAE)は、データをピクセル空間から潜在空間に変換し、その潜在空間から再びピクセル空間に戻す手順を通じてデータを生成・再構築するモデルです。このプロセスでは、エンコーダーとデコーダーという2つの主要なニューラルネットワークが使われ、以下のステップで行われます。
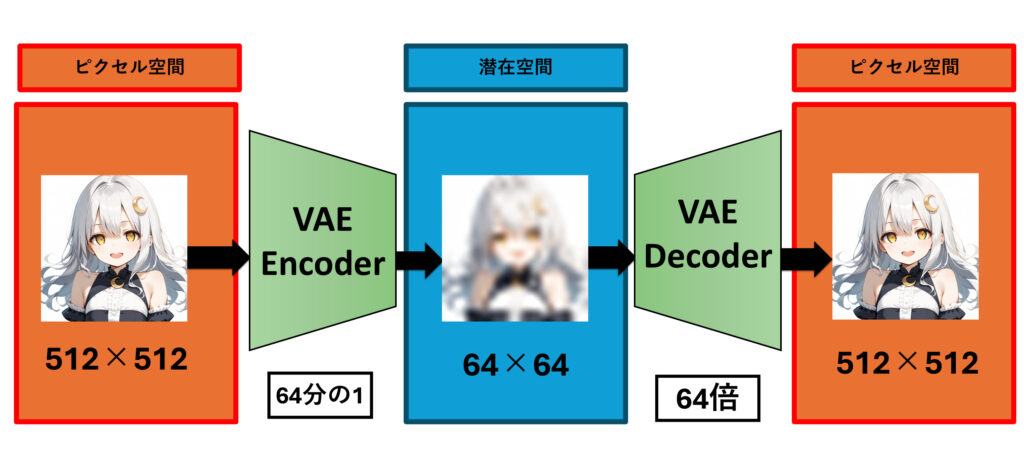
1. ピクセル空間から潜在空間への変換(エンコーダー)
最初のステップでは、VAEのエンコーダーが元のピクセル空間の画像データを潜在空間に変換します。このエンコーダーは、ニューラルネットワークによって構成され、画像データ(ピクセル空間)を入力し、それを低次元の潜在変数にエンコードします。このプロセスの詳細は次の通りです:
- 入力データ: ピクセル空間に512×512のサイズの画像データが入力されます。このデータは通常、画像情報であるので非常に高次元です。
- エンコーダーによる変換: エンコーダーは、ニューラルネットワークを使って入力データを低次元の潜在表現に変換にします。具体的には潜在空間では64×64のサイズの画像として扱われます。元の画像の64分の1のサイズです。エンコーダーは、入力画像を平均と分散というパラメータで表現される潜在変数の分布に変換します。この分布に基づいて潜在表現をサンプリングします。
2. 潜在空間からピクセル空間への戻り(デコーダー)
エンコードされた潜在変数は、デコーダーを通して元のピクセル空間に再構成されます。このデコーダーもニューラルネットワークであり、潜在空間からピクセル空間のデータを生成します。このプロセスの詳細は次の通りです
- 潜在表現: エンコーダーによって得られた潜在変数がデコーダーの入力になります。この潜在変数は、元のデータの低次元表現です。
- デコーダーによる生成: デコーダーは、潜在表現から元のピクセル空間のデータを再構成します。具体的には、デコーダーはニューラルネットワークを使って、潜在空間の情報をピクセル空間に戻すための確率分布を生成します。潜在空間での64×64のサイズの画像から64倍して元の画像と同じ512×512のサイズの画像に再構成されます。
拡散過程
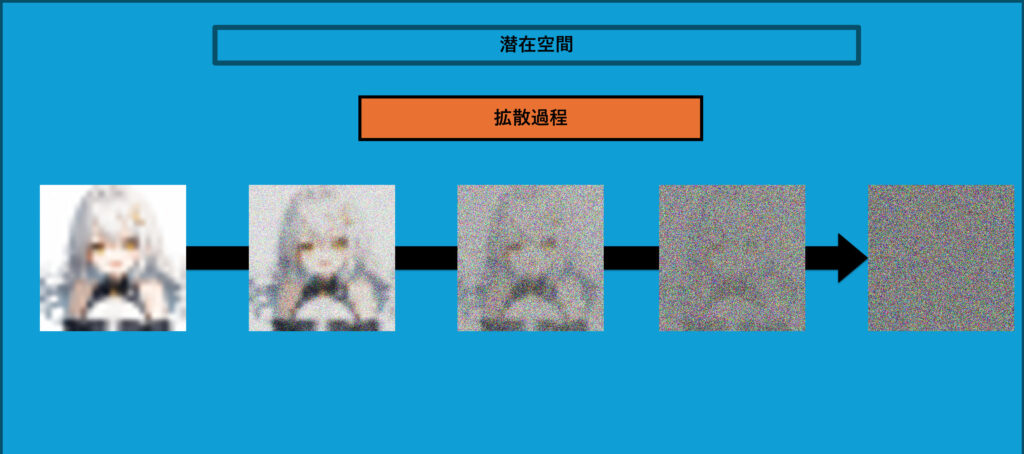
この画像は、潜在拡散モデル(Latent Diffusion Model, LDM)における拡散過程を示しています。この過程は、LDMがどのようにしてノイズを加えながら学習し、画像を扱うかを理解するのにとても重要です。
拡散過程は、モデルが学習するために、画像の潜在表現に少しずつノイズを加えていくプロセスです。最初に元の潜在変数にわずかなノイズを加え、その後徐々にノイズを増やしていきます。最終的には、完全にランダムなノイズが加わった状態になります。
画像に見られるように、最初の画像(左側)ははっきりしていますが、ノイズが加わるにつれて次第にぼやけ、最後にはほとんど何が写っているかわからないランダムなノイズだけの状態になります。
拡散過程の目的
拡散過程には、次のような目的があります。
- 多様性の学習 ノイズを加えることで、モデルがさまざまな状況に対応できるようになります。データにランダムな変動を加えることで、モデルが画像のさまざまな変化を理解し、幅広く対応できる力をつけることができます。
- 潜在表現の訓練 拡散過程によって元の潜在変数が完全にノイズに埋もれた状態になるので、その状態から元の画像を復元する方法を学習します。この過程の後に逆拡散のプロセスを通じて、モデルはノイズが加わっても画像を生成する方法を学びます。
潜在拡散モデルの学習の流れ
- 初期状態からの拡散
- 最初に元の潜在表現があり、それに少しずつノイズを加えていきます。
- 各ステップでノイズが増えると、画像は少しずつぼやけ、ランダムな要素が多くなります。
- ノイズが加えられた状態への到達
- 最終的に、画像はほぼノイズだけになり、元の情報は完全に隠れてしまいます。
- この状態から元の画像を再現することが学習の目標です。
このように、拡散過程は、LDMがデータの潜在表現を深く理解し、ノイズから元の情報を復元する力を身につけるために非常に重要なステップです。この学習を通じて、LDMはノイズが加わっても情報を取り戻し、高品質な画像を生成できるようになります。
拡散過程は、画像を生成する際にデータのランダムな変動を学び、モデルの強さ(頑健さ)を高めるために欠かせません。これにより、LDMはさまざまなタイプの画像に適応でき、多様な生成タスクに応用することができます。
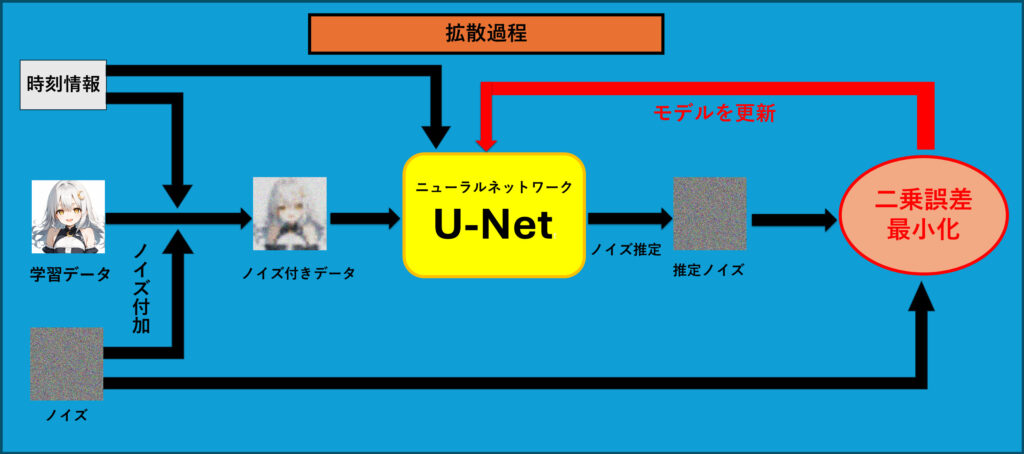
この画像は、潜在拡散モデル(Latent Diffusion Model, LDM)の拡散過程での学習の流れを示しています。このプロセスを理解することは、LDMがどのようにノイズを扱い、ノイズを加えられたデータからノイズを推定し理解ノイズを除去する能力を学習する上でとても重要です。
学習の流れ
以下は、画像に基づいてLDMの拡散過程での学習の詳しい説明です。
- ノイズの付加
- 最初に、左下の「ノイズ」ブロックからランダムに生成したノイズを学習データ(元の画像)に加えます。このとき、時刻情報も一緒に使うことで、ノイズが徐々にデータに追加されていきます。
- これにより、元の画像はだんだんとノイズでぼやけた画像(ノイズ付きデータ)に変わります。このノイズの量は時刻情報でコントロールされており、学習中に少しずつ増加していきます。
- U-Netによるノイズ推定
- ノイズが加えられたデータは、U-Netというニューラルネットワークに入力されます。U-Netは、このノイズ付きデータからノイズの部分を推定します。
- U-Netの目的は、データの中からノイズを特定して、元の潜在表現に戻すためにどの部分がノイズであるかを学習することです。
- ノイズ推定と二乗誤差最小化
- U-Netによって推定されたノイズ(推定ノイズ)と、実際に加えられたノイズの間の差を計算します。この差が小さくなるように、二乗誤差最小化を行います。
- この誤差を最小化することで、U-Netがノイズをより正確に推定できるようにモデルを更新します。この繰り返しにより、ノイズを正確に除去する能力がモデルに備わるようになります。
- モデルの更新
- 最後に、二乗誤差を最小化することで、U-Netのパラメータを調整し、モデルの性能を向上させます。このプロセスを何度も繰り返すことで、U-Netはノイズ付きデータから元のデータをより正確に生成できるようになります。
逆拡散過程
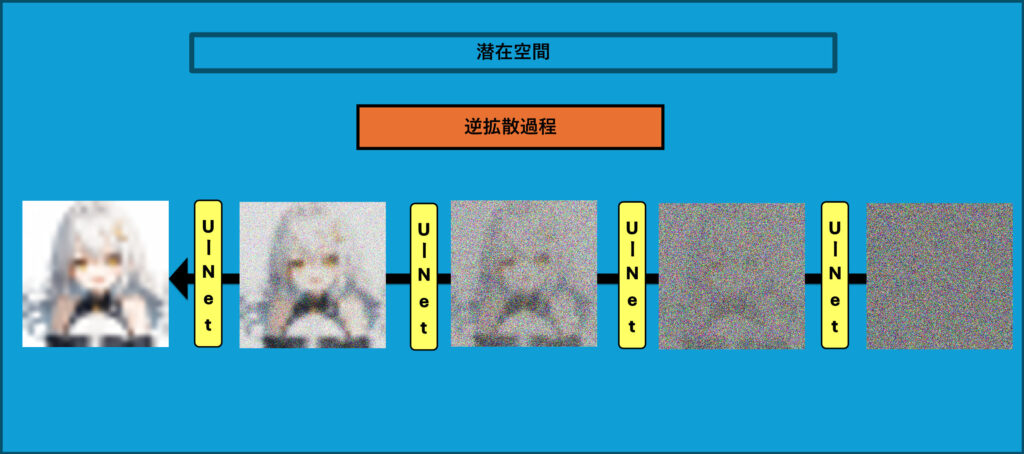
この画像は、潜在拡散モデル(Latent Diffusion Model, LDM)の逆拡散過程での学習の流れを示しています。逆拡散過程は、ノイズを少しずつ取り除きながら元のデータを再構築するプロセスです。このプロセスにより、ノイズから元の画像を再現し、高品質な画像を生成することができます。
逆拡散過程の流れ
以下、この画像に基づいて逆拡散過程の流れを説明します。
- ノイズの除去
- 逆拡散過程の最初の段階では、完全にノイズが加えられた状態の画像からスタートします。右端にある画像はノイズだらけで、元の情報はほとんど隠れています。
- U-Netというニューラルネットワークを使用して、このノイズを少しずつ除去していきます。U-Netは、ノイズの量を予測し、それを減らしていくように設計されています。
- 段階的なノイズの削減
- 画像の各ステップで、U-Netがノイズを少しずつ取り除きます。各ステップごとに画像は少しずつクリアになっていきます。
- 左側に進むにつれて、画像のぼやけが減り、ノイズが少なくなっていく様子がわかります。最終的には、元の画像に非常に近い状態に復元されます。
- U-Netの役割
- U-Netは、ノイズを予測して取り除くために使われる主要なモデルです。U-Netは、ノイズを除去し、画像を元の状態に戻すためにこのプロセスを何度も繰り返して学習します。
- このようにして、U-Netはどの部分がノイズであるかを学び、ノイズを取り除くことで画像を生成する役割を果たします。
逆拡散過程の目的は、完全にノイズが加えられた状態から元の画像を再構築することです。このプロセスを通じて、潜在拡散モデルはノイズを除去する方法を学び、ノイズの影響を受けた画像から新たな画像を生成できるようになります。
逆拡散過程は、潜在拡散モデルが高品質な画像を生成するために必要なステップです。このプロセスによって、モデルはノイズの影響を効果的に除去し、画像を生成するスキルを身につけます。これにより、潜在拡散モデルはノイズに強く、画像を高精度で生成することができるようになります。
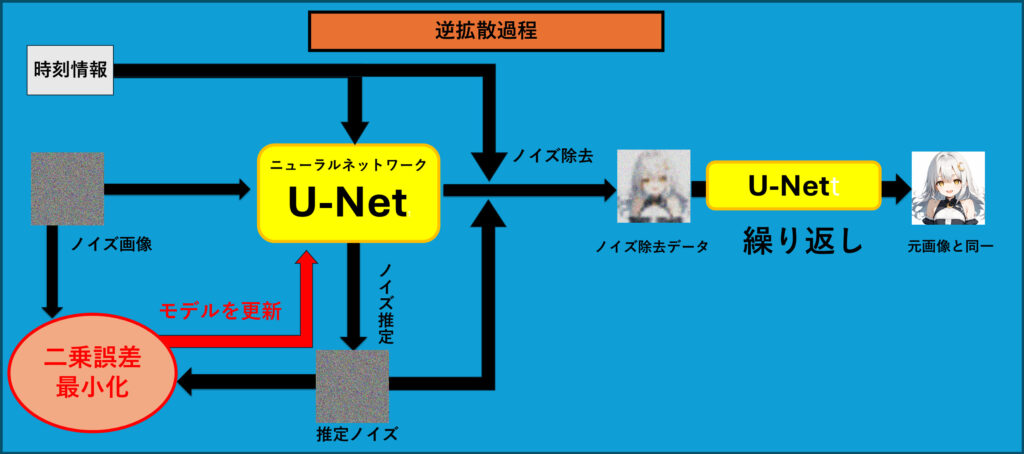
この図は、潜在拡散モデル(Latent Diffusion Model, LDM)の逆拡散過程での学習の流れを示しています。逆拡散過程の学習とは、ノイズを取り除いて元のデータに戻す方法をモデルに学習させるプロセスです。以下で、その流れをわかりやすく説明します。
逆拡散過程での学習の流れ
- ノイズが加えられた画像の入力
- まず、ランダムなノイズが加えられた画像(ノイズ画像)を用意します。このノイズ画像は、元の画像が完全にノイズで覆われた状態です。
- このプロセスでは、各ステップでどれくらいノイズが加えられているかを管理するために、時刻情報を使います。時刻情報は、ノイズの量を示し、各段階でどのくらいノイズを取り除くべきかを決めるのに役立ちます。
- U-Netによるノイズ推定
- ノイズ画像をU-Netと呼ばれるニューラルネットワークに入力します。U-Netは、与えられたノイズ画像から元の画像を再構築するために、どの部分がノイズであるかを推定し、そのノイズの量を計算します(ノイズ推定)。
- U-Netはノイズを正確に推定するように設計されており、各ステップで少しずつノイズを取り除くことを目指します。時刻情報もU-Netに入力され、各段階で適切なノイズ除去の方法を学習します。
- 二乗誤差最小化によるモデルの更新
- U-Netによって推定されたノイズ(推定ノイズ)と、実際に加えたノイズの間の誤差を計算します。この誤差は、二乗誤差として計算されます。
- この二乗誤差を最小化することで、U-Netがノイズをより正確に推定できるように、モデルを更新していきます(モデルの更新)。
- ノイズ除去と繰り返し
- 誤差が少なくなるようにモデルが更新された後、U-Netはノイズを推定して取り除き、ノイズ除去データを得ます。このデータは、元の画像に少しずつ近づく形でクリアになっていきます。
- このプロセスを何度も繰り返すことで、最終的に元の画像と同じクオリティに復元されます(繰り返し)。図の右側に示されているように、最終的にはノイズが完全に取り除かれ、元の画像が再現されます。
逆拡散過程の学習の目的 逆拡散過程の学習の目的は、ノイズから元の画像を正確に再現する能力をモデルに習得させることです。この学習を通じて、LDMはノイズの影響を効果的に除去し、新たな画像を生成するスキルを身につけます。
U-Netの役割
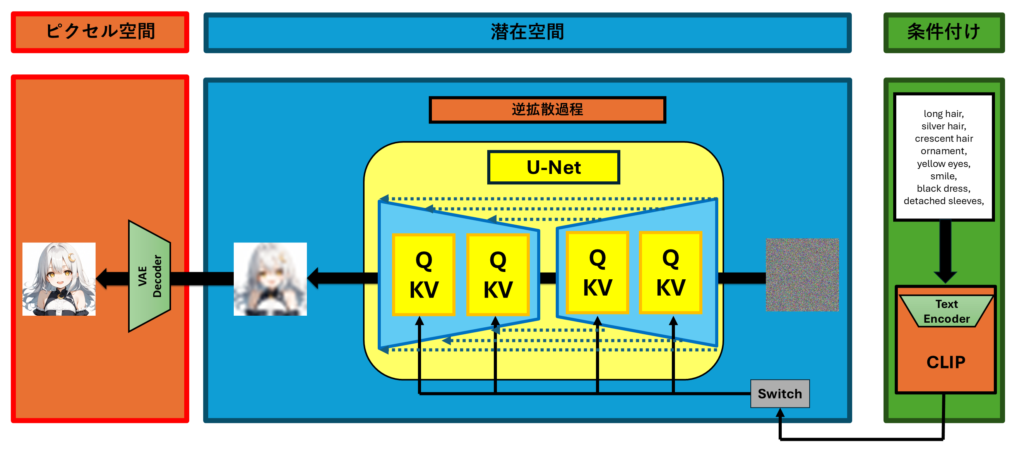
この図は、潜在拡散モデル(Latent Diffusion Model, LDM)における逆拡散過程で、U-Netを使ってノイズを取り除きながらデータを元の状態に戻す構図を表しています。以下、この図に基づいて解説します。
条件付け情報の導入
右側には条件付けとして、画像生成をコントロールする情報(例:髪の色や表情、衣装の特徴など)が示されています。この条件付け情報は、CLIPによって埋め込みベクトルに変換され、U-Netの学習に利用されます。これにより、特定の条件に基づいて画像の生成が行えるようになります。
U-Netによる逆拡散過程の学習
次に、潜在空間でノイズが徐々に加えられた状態から、元の画像を生成するプロセスが始まります。このノイズを取り除く役割を担うのがU-Netです。U-Netは、ノイズが加わった潜在変数を入力として、各ステップでノイズを少しずつ取り除いていきます。
図の中央にある黄色の「Q KV」ブロックは、クエリ(Q)、キー(K)、バリュー(V)を表しており、これはクロスアテンションという仕組みを使って条件付け情報を潜在表現に反映させることを示しています。クロスアテンションにより、条件付け情報(例えばテキストの説明)を活用して、生成される画像の特定の特徴を強調したり調整することができます。
ノイズ除去とモデルの繰り返し更新
ノイズ除去は何度も繰り返されます。この反復の各ステップで、U-Netはノイズを予測し、それを基に潜在表現を少しずつクリーンな状態に戻していきます。この「逆拡散過程」を繰り返すことで、最終的には元の情報に近い潜在表現が得られます。
図中の「Switch」部分は、条件付け情報を適切なタイミングで取り入れることを示しており、条件を使って画像を生成するプロセスを学習することが効果的に行われるようにします。
潜在空間からピクセル空間への再構築
最終的に、ノイズが取り除かれて元の情報に近づいた潜在表現を、VAEのデコーダを使って再びピクセル空間に戻します。こうして、条件に従ってノイズから生成された高品質な画像が得られます。
まとめ
この逆拡散過程を通じて、U-Netはノイズ除去を学び、条件付け情報をうまく使って元の画像を再現する能力を身につけます。これにより、潜在拡散モデルは効率的に高品質な画像を生成できるようになります。また、条件付けによって、ユーザーが指定した特定の特徴を持った画像を生成することも可能です。
生成段階
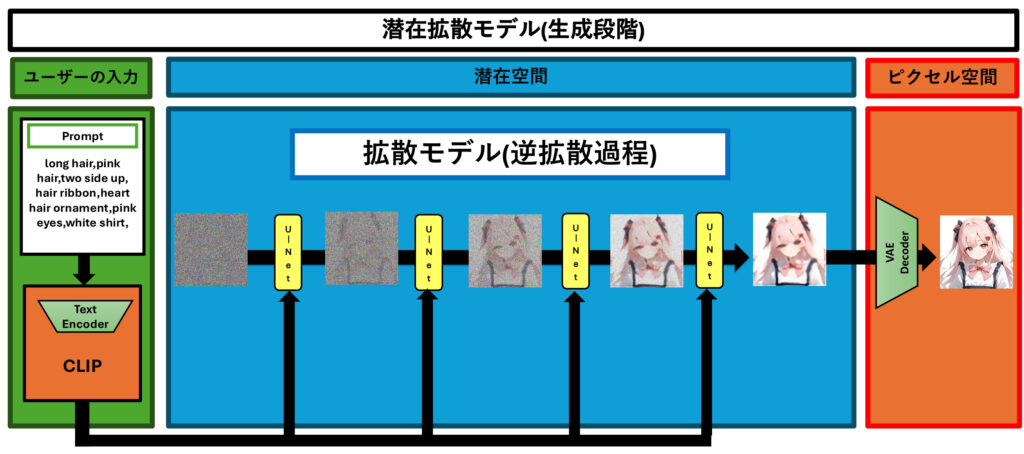
この図は、潜在拡散モデル(Latent Diffusion Model, LDM)を使った画像生成のプロセスを示しています。このプロセスでは、ユーザーが入力した条件に基づいて、高品質な画像を生成します。以下、この図をもとに画像生成の流れを詳しく説明します。
1. ユーザーの入力
左側のブロックには、ユーザーが入力するプロンプト(Prompt)が記載されています。このプロンプトには、「long hair, pink hair, two side up, hair ribbon, heart hair ornament, pink eyes, white shirt」などの条件が含まれており、生成する画像の内容を具体的に指定します。
この条件付け情報は、CLIPによって埋め込みベクトルに変換され、生成プロセスに利用されます。これにより、ユーザーが望む特徴に基づいた画像生成が可能になります。
2. ピクセル空間から潜在空間への変換
ユーザーの条件に従って生成される画像は、まずピクセル空間から潜在空間に変換されます。図の右側には、生成された画像を潜在空間にエンコードする部分が示されています。この変換は、変分オートエンコーダ(VAE)のエンコーダを使って行い、画像の重要な情報を低次元に変換し、効率的に扱えるようにします。
3. 潜在空間での逆拡散過程
次に、潜在空間での逆拡散過程が始まります。最初はノイズが加えられた状態からスタートし、U-Netを使ってノイズを除去していきます。図の中央にある「U-Net」ブロックは、このノイズ除去の各ステップを示しています。
- ノイズを除去する各ステップでは、U-Netがノイズの量を推定し、次第にクリアな状態に近づけていきます。
- ノイズを除去しながら、条件付けされた情報(ユーザーが入力したプロンプト)を反映させて、特定の特徴を持つ画像が生成されます。
図中に見られる複数の「U-Net」ブロックは、ノイズが取り除かれるプロセスが何度も繰り返されることを示しています。この反復によって、ノイズが徐々に減少し、元の条件に近い画像が作られていきます。
4. 潜在空間からピクセル空間への再構築
最後に、ノイズ除去が完了してクリーンな潜在表現が得られた後、その表現をVAEのデコーダを使って再びピクセル空間に戻します。この変換により、ノイズが取り除かれ、ユーザーの条件に従った高品質な画像が最終的に生成されます。
まとめ
この図に示されている潜在拡散モデルの生成プロセスでは、ユーザーが入力した条件に基づいて、潜在空間でノイズ除去のステップを繰り返しながら画像を生成します。このプロセスを通じて、ユーザーが指定した特徴(髪の色や服装、表情など)を持つ高品質な画像を作り出すことができます。潜在拡散モデルは、計算効率を高めつつ、柔軟で制御可能な画像生成を実現する技術です。
U-Netの各層
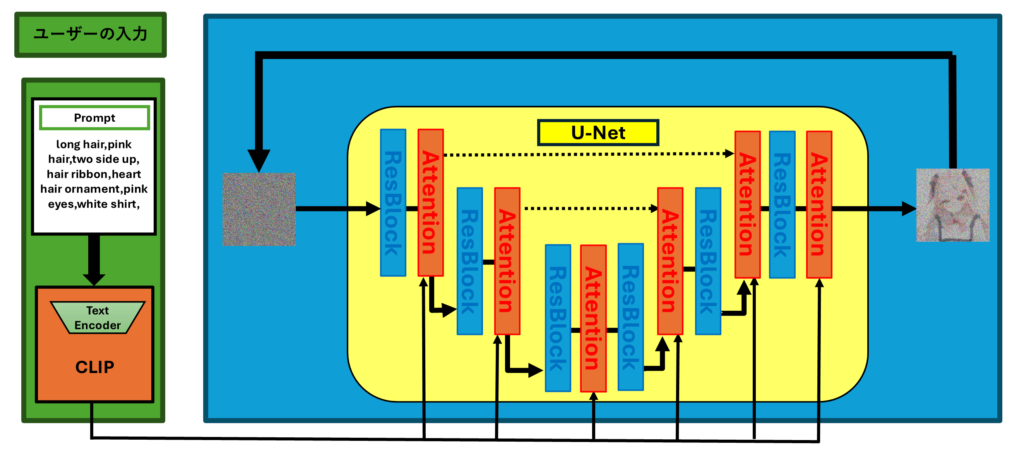
この図は、潜在拡散モデル(Latent Diffusion Model, LDM)における画像生成のプロセスを、特にU-Netの各層の働きに焦点を当てて示したものです。U-Netの各層は、ノイズを除去しながらデータを元の状態にする重要な役割を持っています。以下、この図に基づいて、U-Netの各層がどのようにして画像生成のプロセスに貢献しているのかを詳しく解説します。
1. ユーザーの入力と条件付け
左側のブロックには、ユーザーが入力するプロンプト(Prompt)が記載されています。このプロンプトには、「long hair, pink hair, two side up, hair ribbon, heart hair ornament, pink eyes, white shirt」といった、生成する画像の特徴が具体的に書かれています。この情報は、CLIPによって埋め込みベクトルに変換され、U-Netでの生成に利用されます。これにより、ユーザーの望む特徴が画像生成のプロセスに反映されるのです。
2. 潜在空間でのノイズ処理
生成の最初のステップでは、潜在空間においてランダムノイズの画像の状態からスタートします。これをU-Netを使ってこのノイズを徐々に除去することで、望む画像に近づけていくことが可能です。
3. U-Netの役割
中央のブロック部分が、U-Netの働きを示しています。U-Netは、ノイズを取り除きながら望む画像を生成するために複数のブロックで構成されています。これらのブロックには以下の役割があります
- ResBlock層
ResBlock層は、畳み込みニューラルネットワーク(CNN)に基づいています。ノイズのある入力を次の層に渡しつつ、元の特徴をしっかりと保持する役割を果たします。この層では入力信号を直接次の層に渡すことによって実現されます。これによって元の情報が途中で失われることなく次の層に伝えられ、学習の安定性と効果を高めることが可能です。
ここではノイズを除去しながらも、元の画像の重要な特徴を保持し、それを次の段階で再利用できるようにします。たとえば、生成する画像が持つ特定の形や色の情報がぼやけてしまわないよう、各ステップでその情報を保持し、次の処理ステップに引き継ぐことができます。このことにより、最終的に高品質で詳細な画像が生成されるのです。
ResBlock層は学習の収束を早める効果もあります。特にノイズ除去のプロセスにおいて、過去の情報を適切に保持しつつ次のステップに渡すことで、U-Netはノイズを効率的に取り除きながら、画像の精度を保つことができます。
- Attention層
Attention層はTransformer構造に基づいています。ユーザーの入力したプロンプト(例:「ピンクの髪」「リボン付き」など)といった条件付け情報を、画像の生成プロセスに反映させる役割を持ちます。具体的には、Attention機構は画像のどの部分に特定の特徴が反映されるべきかを集中して処理します。これにより、ユーザーの要求に沿った詳細な画像が生成されるのです。
Attentionは、画像生成の中でどの部分が重要かを自動的に判断し、その部分により多くのリソースを割り当てて処理を行います。この仕組みのおかげで、細部の表現や色の強調が可能になります。たとえば、「目の色」や「髪の装飾」など、細かい部分まで正確に表現することができ、生成された画像の品質が向上します。
通常、生成モデルでは大量の情報を一度に処理する必要がありますが、Attentionはその中から重要な情報を選び出して集中的に処理します。この集中によって、モデルは効率よく描写でき、画像のクオリティを高めることが可能です。これにより、細部まで細かく描写された画像が作られ、全体の一致性も保たれます。
Attentionは、ユーザーが望む特定の特徴に基づいて画像をカスタマイズするための重要な部分です。たとえば、髪の色やスタイル、衣服の詳細など、プロンプトで与えられた条件を考慮し、それを反映した画像を生成します。こうして、ユーザーがイメージしている内容にできるだけ近い画像が生成されるようにします。
U-Netは、この複数のResBlock層とAttention層を組み合わせた層構造を持つことで、画像生成の精度と柔軟性を向上させています。U-Netは畳み込みニューラルネット(CNN) 構造のResBlock層とTransformer構造から来ているAttention層によって構成されています。
各ResBlock層は全体のノイズ除去に集中し、画像の基本的な特徴を保ちながら情報を次に渡します。これにより、モデルは効率的にノイズを取り除くと同時に、画像の元々の質感や形状を失うことなく復元します。
一方、Attention層は、ユーザーの要求を反映して、重要な特徴を強調したり、画像内の特定の部分に集中するための柔軟性を提供します。これにより、条件に基づいて画像の特定の部分をより詳細に制御することができ、ユーザーの意図に合った画像生成が可能となります。
さらに、U-Netは深層のネットワークでありながらも、各層が互いに連携して作業を進めるため、ノイズだらけの潜在空間の情報からでも、ユーザーの条件に基づいた精度の高い画像を生成することが可能です。
4. 逆拡散過程と反復
U-Netはノイズ除去のプロセスを何度も繰り返します。この反復によって、潜在空間でのノイズが徐々に減少し、元の情報に近いクリーンな潜在表現が得られます。図中の複数の「Attention」と「ResBlock」が繰り返し使われていることからも、このプロセスが段階的に行われることがわかります。各Attentionブロックが条件付け情報を反映し、各ResBlockがノイズを除去しつつ画像の生成を行うことで、ノイズだらけの状態からクリアな画像に近づいていきます。
5. 潜在空間からピクセル空間への変換
U-Netによるノイズ除去が完了した後、最終的に得られたクリーンな潜在表現を元に、再びピクセル空間へと変換されます。この変換には、変分オートエンコーダ(VAE)のデコーダが使われ、潜在表現が視覚的な画像に戻されます。こうして、ユーザーが指定した特徴を持つ高品質な画像が生成されるのです。
まとめ
この図は、潜在拡散モデルにおけるU-Netの役割を中心に画像生成の流れを示しています。U-Netは、ノイズを除去しながら、ユーザーの入力したプロンプトに基づいて画像を復元・生成する重要なプロセスです。残差ブロックと注意機構の組み合わせにより、U-Netは効率的にノイズを除去し、条件に合った詳細な画像を生成することが可能になります。この反復的なノイズ除去と条件付け情報の反映によって、潜在拡散モデルは計算効率を保ちながらも高品質な画像生成を実現します。
ResBlock層
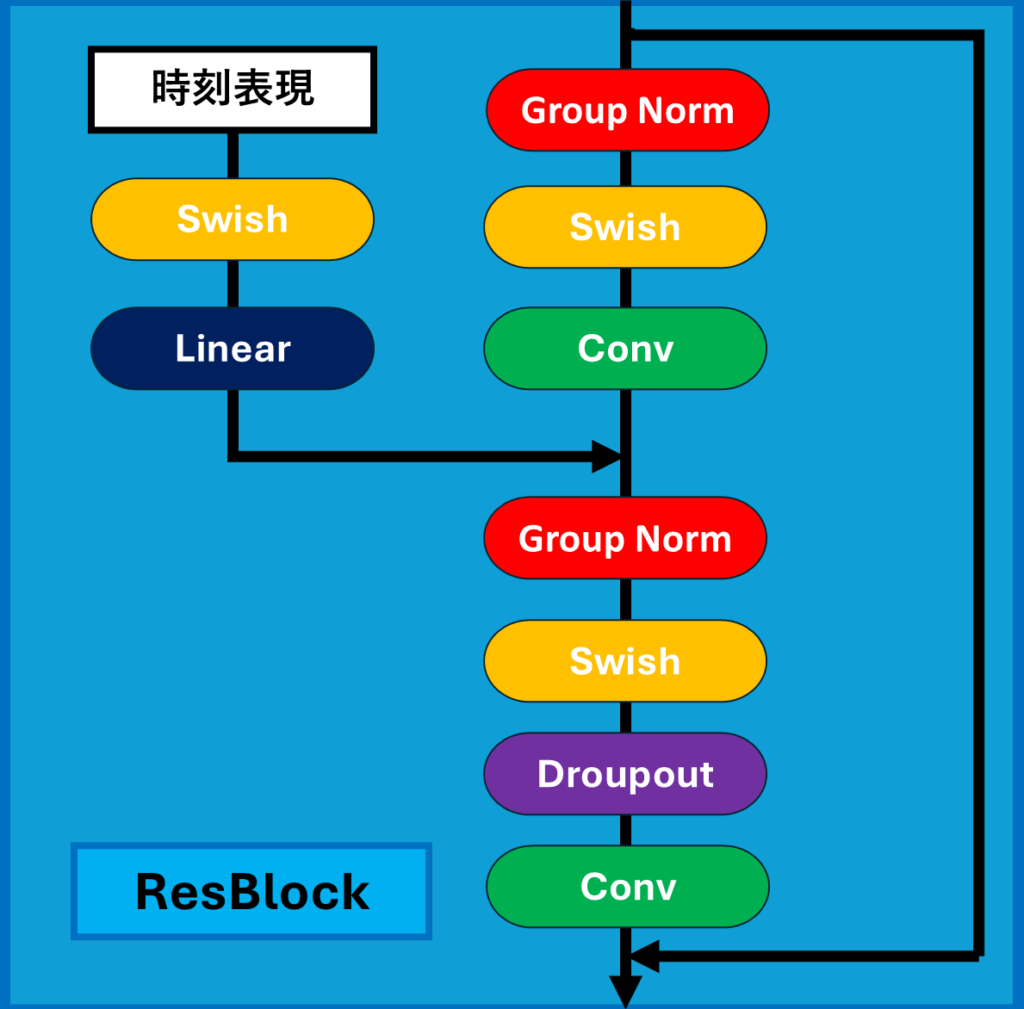
この図は、U-Netを用いた潜在拡散モデル(Latent Diffusion Model, LDM)の画像生成において、ResBlock層がどのように機能しているかを示しています。ResBlock層は、ノイズ除去と画像の特徴の保持を効果的に行うための重要な要素であり、画像生成の精度と効率に大きく貢献します。以下、この図に基づいてResBlock層の各部分の役割について解説します。
ResBlock層の役割
ResBlockは、ノイズを含んだ潜在表現をクリーンな状態に近づけるための一連の処理を行います。この図の流れを追いながら、各部分の役割を見ていきましょう。
1. 時刻表現の導入
- 左上には「時刻表現」というブロックがあります。これは、拡散モデルにおいてノイズを加えたり除去する際の「時間」情報を表しています。この情報は、各ステップでノイズをどの程度除去するかを制御するために使用されます。
- 時刻表現は、Swish関数とLinear層を通して処理され、ResBlock内の他のパラメータに反映されます。これにより、時間に応じた動的な調整が行われます。時刻表現を導入することにより、モデルは各ステップでのノイズ除去の度合いを柔軟に調整でき、より自然な画像生成を実現します。
2. Group Norm(グループ正規化)
- 図の赤いブロックで示されているのがGroup Normです。これは、グループごとにデータの正規化を行うことで、学習の安定性と効率を向上させます。正規化により、各層でのデータのスケールを整えるため、次の処理ステップで適切な範囲内で計算が行われるようにします。
- 正規化は、ネットワーク内の異なる層で一貫したデータ分布を維持し、モデルの学習をスムーズに進めるために非常に重要です。Group Normを用いることで、バッチサイズに依存しない安定した正規化が可能となり、特に小規模なバッチサイズでの学習時に効果的です。
3. Swish(活性化関数)
- Swishは、活性化関数として使われており、各ニューロンの出力に非線形性を加えます。この非線形性により、ネットワークはより複雑な特徴を学習することが可能になります。Swish関数は、⁻データのマイナスの数値をほぼゼロにしてゼロ以上の部分を強調しながらも、滑らかな出力を持つため、より効果的な特徴学習が可能です。
- Swishの特性により、活性化されたデータはより豊かな表現力を持つようになります。これは、生成された画像の細部に対して、より柔軟で精細な特徴を学習できることを意味します。
4. Conv(畳み込み)
- 図の緑色のブロックで示されるのがConv(畳み込み層)です。畳み込み層は、データから空間的な特徴を抽出する役割を持っています。画像の中のエッジや形状といった重要な要素を捉え、それを次の層に渡していきます。
- Conv層は、フィルタを使って入力データをスライドしながら特徴を抽出します。この特徴抽出プロセスは、画像生成において非常に重要であり、画像が持つ重要なパターンやテクスチャを捉えることができます。これにより、生成された画像の細部がよりリアルで説得力のあるものになります。
5. Dropout(ドロップアウト)
- Dropoutは、過学習を防ぐための手法です。ランダムに一部のニューロンを無効化することで、ネットワークが特定の特徴に過度に依存することを防ぎます。これにより、ネットワークは過学習を防ぎより汎化能力が高まり、見たことのないデータにも対応できるようになります。
Linear(線形変換)
Linearは入力データに線形変換を適用し、出力を次の層に適切な形でデータを渡す役割があります。
残差接続
- ResBlockの重要な特徴の一つが、残差接続です。この接続は、入力された情報をそのまま次の層に渡す役割を担っています。図で示されているように、処理後のデータに対して、入力データを加算することで、学習の安定性が増します。
- 残差接続により、ノイズ除去の際に過度に情報が失われることなく、元の特徴が保持されます。これによって、ネットワークは「元の情報を残しながら、ノイズを効果的に除去する」ことが可能となります。
ResBlock層の全体的な流れ
- 最初に入力されたノイズ付きの潜在表現は、Group Normを通してスケールを整え、Swish関数で活性化されます。
- 次に、Conv層を通して空間的な特徴が抽出され、再度Group Norm、Swish、Dropout、そしてもう一度Convが適用されます。
- 最後に、最初の入力が残差接続を通して加算され、次の処理ステップに渡されます。
- この一連の流れを通して、ResBlockはノイズを徐々に除去し、元の特徴を失うことなく、潜在表現をクリーンな状態へと導いていきます。
まとめ
このResBlock層は、潜在拡散モデルにおいて非常に重要な役割を果たしています。ノイズを除去しながらも元の情報を保持するための一連の処理を行うことで、画像生成の精度と品質を大幅に向上させます。Group Normによるデータの安定化、Swishによる非線形性の付加、Convによる特徴抽出、そしてDropoutによる汎化能力の向上が、U-Net全体の性能を支えています。
このようにして、ResBlock層は潜在拡散モデルの画像生成において、データの持つ重要な特徴を失うことなく、徐々にノイズを除去してクリーンな状態へと導くプロセスを実現しています。さらに、残差接続を通じて、学習の安定性を確保し、ネットワークが深くなっても安定して効果的な学習を進めることができます。こうしたResBlock層の働きにより、潜在拡散モデルは高品質で精細な画像を生成することが可能となり、ユーザーの要求に応じた柔軟な画像生成を実現しています。ResBlock層は、ノイズを除去しながら情報の流れを途切れさせず、深層学習の持つ課題を克服するための重要な構成要素であり、その効率性と効果は、最終的な画像生成の品質に直結しています。
Attention層
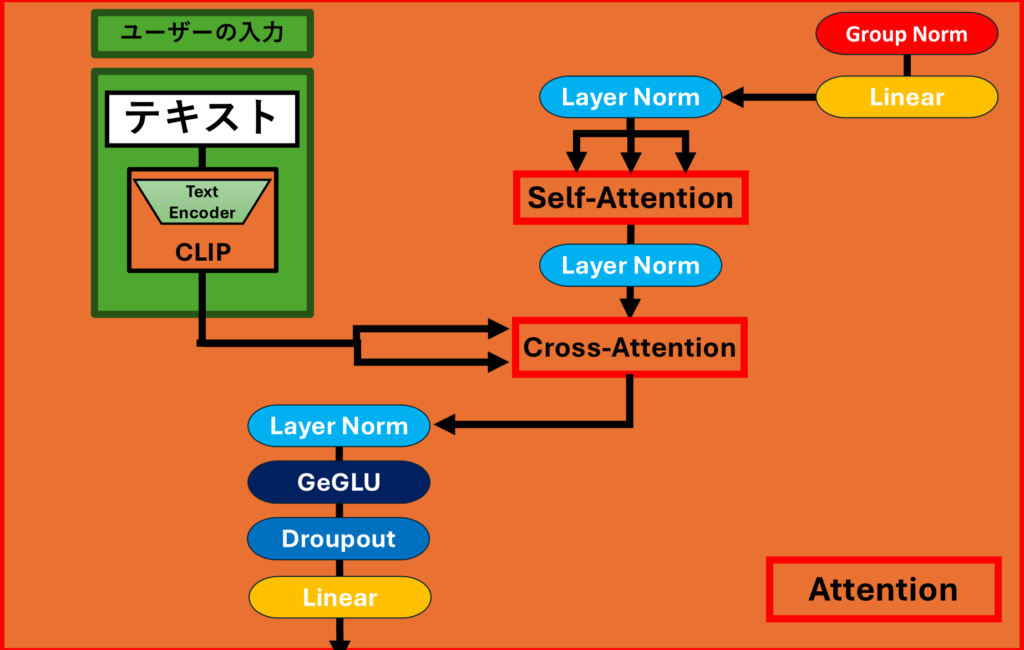
この図は、潜在拡散モデル(Latent Diffusion Model, LDM)の画像生成において、U-NetのAttention層がどのように働いているかを示しています。Attention層は、ノイズを除去しながら特定の特徴を強調するために使われ、ユーザーの入力した条件に基づいて画像を生成する重要な役割を果たしています。以下、この図に基づいて、Attentionの働きを解説します。
Attention層の役割
1. ユーザーの入力
- 図の左側にある緑色のブロックには、ユーザーが入力する「テキスト」が示されています。例えば、「long hair, pink hair,」など、生成したい画像の具体的な特徴が記載されています。
- このテキスト情報は、CLIPとを通して埋め込みベクトルに変換され、後のプロセスで画像生成に使用されます。この情報を使うことで、ユーザーの希望する条件が反映された画像を生成することが可能になります。
2. Self-AttentionとCross-Attention
- Attention層には、Self-AttentionとCross-Attentionという2つの重要なAttention機構が存在します。これらは、異なる役割を持ちながらも、画像の品質を向上させるために協力して機能しています。
- Self-Attention(自己注意機構):
- 図の中央にある「Self-Attention」は、U-Net内部で各部分が相互にどのように関連しているかを見つけ出す役割を果たします。生成される画像内で各ピクセルが他のピクセルとどのように関係しているかを計算することです。この相互関係を理解することで、画像のさまざまな部分が相互に関連し合って、一貫した、整合性のある出力を生み出すことができます。例えば、髪の色、目の形、服の柄などが、各部位が独立しているのではなく、一つのまとまりとして調和して見えるように生成されます。
- 具体的には、Self-Attentionは各ピクセルに対して他のすべてのピクセルとの関連度を計算し、その関連度に応じて重み付けを行います。これにより、特定の部分が重要であれば、その部分により多くの注目が集まるようになり、生成される画像における重要な特徴が強調されます。
- Cross-Attention(交差注意機構):
- Cross-Attentionの役割は、ユーザーが入力したテキスト情報と、生成される画像内の各部分を効果的に関連付けることです。このプロセスにより、ユーザーの入力に忠実な画像が生成されます。具体的には、ユーザーが例えば「ピンクの髪」や「ハートの髪飾り」といった条件を入力した場合、Cross-Attentionはこれらの情報を利用して画像中のどの部分にどのような特徴を追加するかを指示します。この方法で、ユーザーの要求に応じてピクセルレベルでその条件を適用し、生成される画像が要求に合ったものとなります。
- Cross-Attentionは、テキスト条件を使って、どの部分にどのような特徴を付与するべきかを指示するため、生成される画像がユーザーの入力に忠実であるようにします。例えば、「ピンクの髪」を指定した場合、その情報が正確に髪の部分に反映されるようにする役割を果たします。
3. Layer Normalization
- Layer Norm(レイヤー正規化)は、Attention層に入る前後で使用されています。Layer Normは、レイヤーごとにデータを正規化することで、ネットワークの学習を安定化させます。これにより、ネットワーク全体のパフォーマンスが向上し、計算の安定性が高まります。
4. Attention層の流れと処理
- 図の中で、「Layer Norm」「Self-Attention」「Cross-Attention」などが繰り返し使われていることがわかります。これは、Attention層を通じて、何度もテキスト条件と画像の特徴を組み合わせていくプロセスを示しています。
- Attention層は、生成される画像の各部分が他の部分とどのように関連し、どのようにユーザーの条件に基づいて変化するかを調整します。この反復的な処理により、画像全体が一貫性を持ち、ユーザーの指定する特徴を正確に反映したものになります。
5. GeGLUとDropoutとLinear
- 図の下部には、GeGLU(Gated Linear Units)とDropoutとLinearが示されています。これらの要素もAttention内で使用され、ネットワークの性能向上に貢献します。
- GeGLUは、Attentionの出力にさらなる非線形性を加え、より複雑なパターンを学習できるようにします。
- Dropoutは、過学習を防ぐために、一部のニューロンをランダムに無効化し、ネットワークの汎化能力を高めます。これにより、モデルが未知のデータに対しても適切に対応できるようになります。
- Linearは、入力されたデータを線形変換して出力し、次の層に渡す役割を持ちます。
まとめ
この図で示されているU-NetのAttention層は、画像生成において極めて重要な役割を担っています。Self-Attentionにより画像内のピクセル同士の関連を考慮し、Cross-Attentionによりユーザーの入力した条件を反映させることで、生成される画像がより自然で、かつ条件に沿ったものとなります。また、Layer NormalizationやGeGLU、Dropoutなどの要素が組み合わさることで、ネットワーク全体の学習が安定し、結果的に高品質な画像が生成されます。
こうしたAttentionの機能によって、潜在拡散モデルはユーザーの要求に応じて柔軟に対応し、細かな条件も忠実に再現した高品質な画像生成を実現しています。
Self Attention
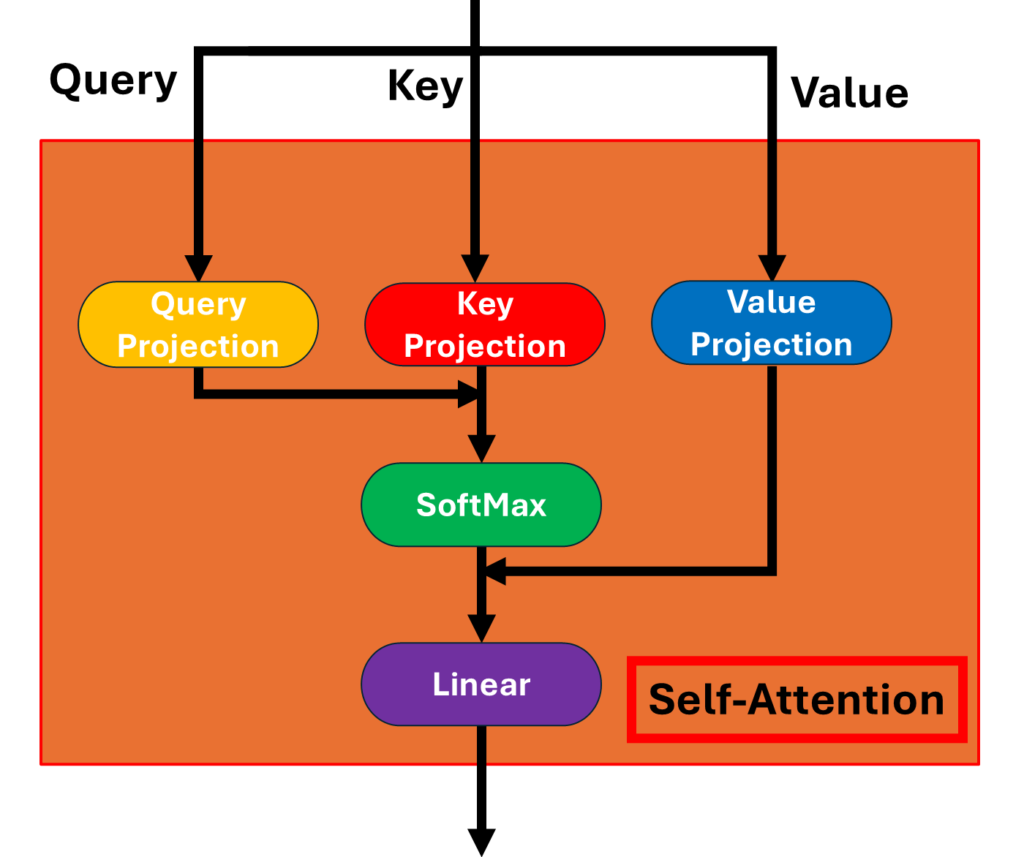
この図は、潜在拡散モデル(Latent Diffusion Model, LDM)の画像生成において、Self-Attention(自己注意機構)がどのように働くかを示しています。Self-Attentionは、画像を生成するときに各ピクセルが他のピクセルとどのように関連しているかを理解するために重要な役割を果たします。このプロセスにより、画像内の情報が統合され、より自然で精密な画像が生成されることが可能になります。以下、この図に基づいてSelf-Attentionの働きについて詳しく説明します。
Self-Attentionの役割
1. Query, Key, Valueの概要
- Self-Attentionでは、入力した画像はニューラルネットワークを通り「Query(クエリ)」、「Key(キー)」、「Value(バリュー)」という3つの異なるデータに変換されます。これら3つは、画像内で他の情報との関連性を測定するために使われます。
2. Query, Key, Valueの投影
- 図の黄色、赤、青のブロックは、「Query(クエリ)」、「Key(キー)」、「Value(バリュー)」の入力をそれぞれQuery Projection、Key Projection、Value Projectionに変換する工程を表しています。これにより、各ピクセルの注意度や重要度、持っている情報を数値化し、次の処理に利用します。
3. Attentionの計算
- Self-Attentionでは、QueryとKeyを使って各ピクセル間の関連度を計算します。この関連度は、各ピクセルが他のピクセルにどれだけ注意を向けるべきかを示すものです。
- 図のSoftMaxブロックでは、この関連度に基づいて重み付けが行われます。SoftMax関数は、各ピクセルの関連度を0から1の間に正規化し、各ピクセルがどれだけ他のピクセルから情報を引き出すべきかを決定します。
4. Valueの加重合計
- 各ピクセルのValueは、関連度に基づいて重み付けされ、加重合計されます。関連性の高いピクセルはより多くの影響を受け、関連性の低いピクセルは影響が小さくなります。これにより、あるピクセルが他のピクセルからどのように影響を受けるかが反映され、全体として一貫性が保たれた画像が生成されます。
5. 線形変換
- 最後に、図のLinearブロックを通して、Self-Attentionの出力が線形変換されます。この変換は、Attentionの結果を次の層に適切に引き渡すための準備を行います。
Self-Attentionの重要性
Self-Attentionの仕組みは、画像全体のピクセルが互いにどう影響し合うかを計算することで、画像に統一感を与え、より自然な仕上がりにするために非常に重要です。例えば、髪の色や目の形などの特徴が画像全体で整合性を保ちながら再現され、高品質で詳細な画像が生成されます。
このプロセスにより、ユーザーが入力した条件に基づいた特徴が画像全体に正確に反映され、自然で一貫性のある生成結果を得ることが可能になります。各ステップでピクセル間の関連性を考慮することで、生成される画像はより洗練され、細部まで統一感のあるものとなります。
Cross-Attention
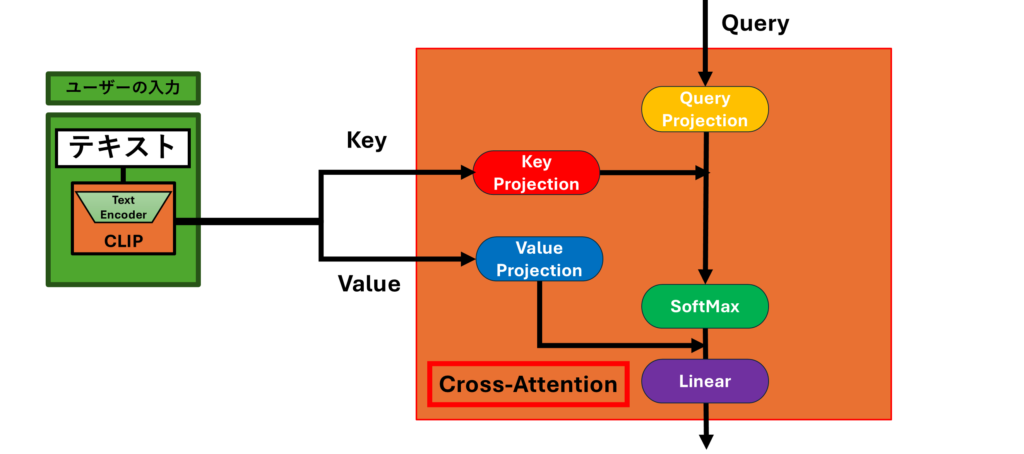
この図は、潜在拡散モデル(Latent Diffusion Model, LDM)の画像生成におけるCross-Attentionの働きを示しています。Cross-Attentionは、Self-Attentionとだいたい同じ処理を行っていますが、Self-Attentionと異なる部分として生成中の画像の情報だけではなく、ユーザーのテキストによる指示の情報も反映されます。そのためCross-Attentionはユーザーが入力したテキスト情報を生成する画像に反映させるために非常に重要な役割を果たしています。以下、Cross-Attentionの仕組みとその役割について詳しく解説します。
Cross-Attentionの概要
Cross-Attentionは、テキストの条件と潜在変数を結びつける役割を持つAttentionメカニズムです。この仕組みによって、生成される画像がユーザーの入力に応じた内容になるように、画像中の各部分が条件に合った特徴を持つようになります。
1. テキスト入力の処理
- 図の左側には「テキスト」のブロックがあります。ここでは、ユーザーが入力した具体的な条件(例: “long hair, pink hair” など)が示されています。
- このテキストは、CLIPというテキストエンコーダに入力され、その特徴を埋め込みベクトルに変換されます。この埋め込みベクトルは、次の処理ステップでCross-Attentionのキー(Key)およびバリュー(Value)として使われます。
2. Query, Key, Valueの生成
- Cross-Attentionは、「Query(クエリ)」、「Key(キー)」、「Value(バリュー)」という3つの要素を使います。
- Queryは、生成中の画像の特徴(生成途中の潜在変数)に基づいて生成されます。これは、生成する画像がテキスト条件に対してどれだけ注目すべきかを決定するためのものです。
- KeyとValueは、テキスト情報から生成され、テキスト条件の重要性や関連性を表します。
3. Query, Key, Valueの投影
- 図の黄色、赤、青のブロックは、それぞれ「Query Projection」、「Key Projection」、「Value Projection」を示しています。これはそれぞれ「Query(クエリ)」、「Key(キー)」、「Value(バリュー)」を投影しています。
4. Attentionの計算
- QueryとKeyを使って、テキスト条件と画像中のどの部分がどれだけ関連しているかを比較して計算します。この関連度は、どのテキスト条件がどの画像の部分に影響を与えるかを決定します。
- 図のSoftMaxブロックでは、計算された関連度に基づいて重み付けを行います。これにより、画像生成の際に、どの情報がどの部分で強調されるべきかが決定されます。
5. 加重合計と線形変換
- Valueに関連度に基づく重みをかけた加重合計が行われます。Valueはテキスト情報に由来しています。これにより、画像中の各ピクセルがどれだけテキスト条件から影響を受けるかが反映されます。
- 最後に、Linearブロックで線形変換が行われ、Attentionの出力が次の層に適切に伝えられます。
Cross-Attentionの重要性
Cross-Attentionの役割は、生成される画像がユーザーの入力に沿うようにテキスト条件を反映させることです。このメカニズムにより、ユーザーが指定した条件(例えば、「ピンクの髪」など)が画像中の対応する部分に適切に反映され、結果的に条件に忠実な画像生成が可能となります。
Cross-Attentionが適切に機能することで、画像全体に統一感が生まれ、各特徴が自然に表現された高品質な画像が生成されます。この仕組みは、潜在拡散モデルにおける画像生成において、ユーザーの要求を正確に反映するための重要な要素となっています。
Stable Diffusion XL(SDXL)
Stable Diffusion XL(SDXL)についても触れておきます。Stable Diffusion XL(SDXL)は、従来のStable Diffusion1系などのシリーズに比べて大幅に改良されたバージョンです。この項目では、SDXLの主な特徴や改善点について項目ごとに解説します。
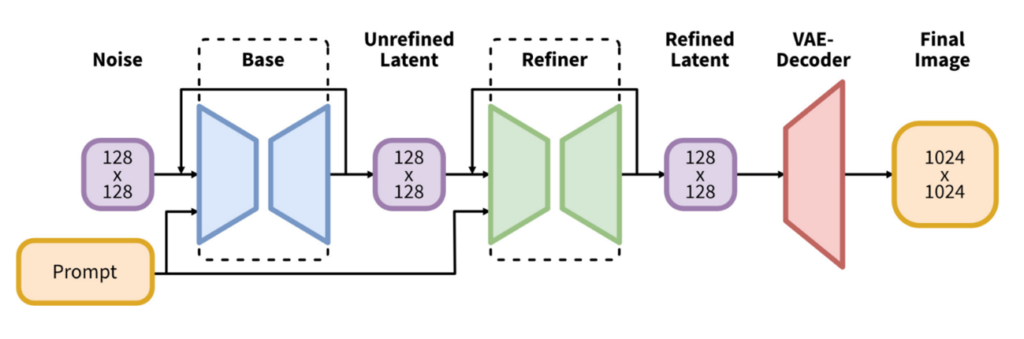
モデルサイズとアーキテクチャの拡大
SDXLでは、前バージョンに比べてU-Netのバックボーンが約3倍の大きさに拡張されています。これにより、モデルがより複雑で高品質な画像を生成でき、精緻な結果が得られるようになりました。また、アーキテクチャ全体のパラメータ数も大幅に増加しており、モデルが詳細な特徴を学習する能力が向上しています。
さらに、Transformerブロックの数が増加し、Transformerの計算が多く行われるように改良されています。この変更により、計算効率が向上し、画像生成のディテールがさらに改善されています。
複数のテキストエンコーダの使用
SDXLでは、テキストエンコーダとしてCLIP ViT-Lに加えて、新たにOpenCLIP ViT-bigGを使用しています。この2つのエンコーダを組み合わせることで、より豊かな条件付けが可能になり、ユーザーの意図に沿った自然な画像生成が実現されています。また、テキストエンコーダの出力をチャネル方向に結合して使用することで、条件付けの精度が向上しています。
改善されたAttention機構
従来のSD1系モデルでは、Attentionに含まれるTransformerブロックは各レイヤーに1つだけでしたが、SDXLでは複数のTransformerブロックを組み込んでいます。これにより、より複雑な処理が可能となり、画像生成の質がさらに向上しています。
Micro-Conditioning
複数のアスペクト比を扱うために、新しい条件付けの手法であるMicro-Conditioningが導入されています。この手法により、異なるサイズや形状の画像にも柔軟に対応し、高品質な画像を生成できるようになりました。ユーザーのプロンプトに応じた細かい条件付けが可能となり、生成結果の精度がさらに向上しています。
リファイナー(Refiner)モデルの導入
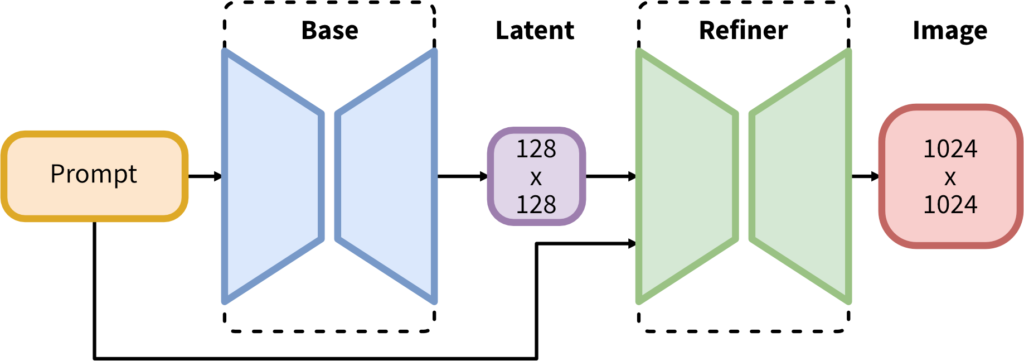
出典:stabilityai/stable-diffusion-xl-base-1.0
SDXLでは、Baseモデルで生成された画像をさらに精密に修正するために、リファイナー(Refiner)モデルが導入されています。このリファイナーは、生成された画像のテクスチャや細部を精緻にすることで、高品質な出力を実現します。これにより、生成された画像のディテールがより洗練され、リアルな質感とクオリティが向上しています。
6. デュアルステージ生成
SDXLの画像生成プロセスは、二段階のパイプラインで処理されています。まず、Baseモデルで画像の主要な構造を生成し、その後にRefinerモデルでテクスチャや細部を修正します。このデュアルステージアプローチにより、生成の効率と品質が大幅に向上しています。
7. マルチアスペクトトレーニング
SDXLは、異なるアスペクト比の画像を扱うためのマルチアスペクトトレーニングを採用しています。この手法により、縦長や横長の画像など、さまざまなアスペクト比に対応できるようになりました。データセットを異なるアスペクト比のバケットに分け、それぞれのバケットから訓練バッチを構成することで、多様な出力に対応する能力を向上させています。 SDXLは、これらの改良により従来のStable Diffusionモデルと比べて、より高解像度で詳細な画像生成を実現しています。複数のテキストエンコーダの併用やリファイナーモデルの導入により、ユーザーの要求に忠実な画像を生成できる点が大きな特徴です。また、マルチアスペクトトレーニングによって、さまざまな画像サイズにも対応できる柔軟性を持つことが強調されています。これにより、SDXLは従来のStable Diffusionモデルを超える表現力と品質を持つ、次世代の画像生成モデルとして注目されており、現在ローカルで主流の画像生成として使っている層も存在します。
最後に
最後に表紙画像にも使ったイラストの格Stepsごとの生成過程について載せておきます

まとめと感想
この記事では、画像生成AIの技術について詳しく解説しました。特に、拡散モデルがどのように画像生成の中心的な役割を果たしているのかを説明し、CLIPやU-Net、VAEなど、さまざまな技術がどのように連携して高品質な画像生成を可能にしているかを学びました。また、潜在拡散モデル(LDM)についても、どのように計算コストを抑えながらリアルな画像を生成できるか、その仕組みを理解していただけたと思います。そして、最新の技術であるSDXLに触れることで、画像生成AIがどのように進化し、次の段階に向かっているのかを確認することができました。
潜在拡散モデル(LDM)は、従来のピクセル空間での処理に比べて、より効率的に低次元の潜在空間で計算を行うことによって、計算コストを削減しながらも高品質な画像を生成する技術です。この技術を使うことで、画像生成AIは大規模なデータを効率的に扱うことができ、実用性が大きく向上しました。この記事では、潜在拡散モデルの学習段階と生成段階についても触れ、AIがどのようにノイズを取り除きながら画像を生成するのか、そのプロセスを分かりやすく説明しました。
生成AI技術の進歩によって、AIがより身近な存在となり、社会全体にとって重要なツールになりつつあります。Stable DiffusionやSDXLといった最新のモデルを使うことで、単に画像を作り出すだけでなく、ユーザーの意図に従って特定の要素を加えたり、細部にこだわった表現を作り出すことが可能になっています。その結果、新たなインスピレーションを得て、これまでにない方法でアイデアを形にすることができるようになり、制作プロセス自体にも新しい可能性が生まれています。
潜在拡散モデルのアプローチは、単にピクセルを並べるのではなく、潜在空間と呼ばれる、より抽象的で効率的な方法で画像を作り出すものです。この方法により、画像生成のスピードが速くなり、より高品質な画像が得られるようになりました。これにより、画像生成AIは単なる研究対象から、実際の産業やクリエイティブな場面で使える実用的なツールへと進化しています。この技術は、製品デザイン、広告、ファッション、さらには仮想世界の構築といった様々な分野での利用が期待されており、それぞれの分野で新たな価値を生み出す可能性を秘めています。
生成AIの未来の可能性は非常に大きく、私たちの生活に様々な変化をもたらすことでしょう。例えば、デザインの自動化や、ゲームや映画といったエンターテインメント分野での新しい表現の創造、さらには教育や医療などの分野での応用が期待されています。AIは単に効率を上げるための道具ではなく、人々の創造性をサポートし、新たなアイデアを形にするための強力なツールとなります。教育分野では、AIが学習教材を自動で作成したり、個々の生徒に合わせた教育プランを提供することが考えられ、医療分野では、患者のニーズに合った医療画像の生成や、治療のシミュレーションなど、さまざまな形で活用が期待されています。これにより、私たちの日常生活においても、AIが新たな可能性を切り開く手助けをしてくれることでしょう。
そして、これから次世代の画像生成技術として期待されているのが「拡散トランスフォーマー」です。拡散トランスフォーマーは、拡散モデルの強力な生成能力とトランスフォーマーの優れた理解力を組み合わせた新しい技術です。このアプローチによって、画像生成AIはさらに複雑な指示やコンテキストに対応し、より高度で柔軟な生成が可能になるとされています。これにより、生成AIはさらに高度なクリエイティブプロジェクトにも対応できるようになり、私たちの創造活動をこれまで以上に支える存在となることが期待されています。
本記事が、これらの新しい技術を理解し、AI技術のさらなる応用や創造の可能性を見つける手助けになれば幸いです。生成AIはこれからも進化を続けていくでしょうし、その進化によって、私たちの生活や仕事の中でより大きな役割を果たしていくことでしょう。この記事を通して得た知識が、生成AIを使って新しいクリエイティブな挑戦に取り組むための基礎となることを願っています。AIは単なるツール以上の存在となり、私たちと共に学び、共に創造するパートナーとして、未来の創造に向けた重要な役割を果たしてくれるはずです。その未来に向けて、共に歩んでいきましょう。
参考資料
論文
政府資料・公的資料
Webサイト
書籍
- 拡散モデル データ生成技術の数理, 岡野原大輔, 岩波書店,2023/2/18
動画