
この記事は以下の論文を紹介したものです。
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin,”Attention Is All You Need”,

Transformerの登場
これまでの機械翻訳や自然言語処理の分野では、リカレントニューラルネットワーク(RNN)やLSTMネットワークが主な技術として広く使われてきました。これらのモデルは、入力されたシーケンスを一つずつ順番に処理することで文脈を理解し、翻訳や文章生成などのタスクを行います。しかし、この一つずつの処理は特に長い文を扱うときに非常に時間がかかり、効率が悪いという問題がありました。
この問題を解決するために、多くの研究者が注意メカニズム(Attention Mechanism)を使って改善しようとしました。注意メカニズムは、入力の中で重要な部分に注目することで、全体の関係性をより効果的に学習することを目指しています。しかし、従来のモデルは注意メカニズムとリカレント構造を組み合わせていたため、並列処理のメリットを十分に活かせていませんでした。
そのような状況の中で登場したのが、Transformerです。Transformerはリカレント構造や畳み込みを使わず、注意メカニズムだけを使う新しいアーキテクチャです。これにより、入力全体の依存関係をグローバルに捉えることができ、リカレントモデルに比べて大幅に効率的な並列処理が可能になりました。特に、機械翻訳の分野で優れた成果を上げています。 Transformerの成功は、従来の限界を打ち破り、自然言語処理だけでなく、画像認識や音声処理といった他の分野にも大きな影響を与える可能性があります。このシンプルで強力なアーキテクチャは、機械翻訳をはじめとした多くの自然言語処理タスクにおいて従来の最先端モデルを超える成果を示し、AI技術の進化における重要なターニングポイントとなりました。
イントロダクション
これまでのシーケンス変換モデル(ここでのシーケンスとは、時間的または順序的に並んだデータの一連の流れを指します。例えば、文章中の単語の並びや音声信号などがシーケンスに該当します)は、リカレントニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)を基盤にしていました。これらの手法は、自然言語処理や機械翻訳など、連続したデータの処理に非常に有効でしたが、いくつかの大きな課題がありました。
RNNや、その改良版であるLSTMやGRUなどのモデルは、シーケンス内のトークンを一つずつ順番に処理するため、どうしても計算が一つずつ順番に処理するになってしまいます。この順番に処理する性質のため、特にシーケンスが長くなると計算に時間がかかり、効率が悪くなるという問題がありました。また、CNNを使ったモデルでも、長いシーケンスの依存関係を効果的に学習するには多くの層が必要で、その分計算コストが高くなってしまうという課題がありました。
こうした問題を解決するために、新たに求められていたのが、シーケンス(データの順序を持つ連続した流れ)全体の依存関係を効率よく学習し、さらに並列処理が可能なアプローチです。その解決策として提案されたのが、Transformerです。Transformerは自己注意機構(Self-Attention)を中心としたアーキテクチャであり、従来のリカレント構造を完全に排除しました。これにより、シーケンス内の任意の位置同士での情報のやりとりが可能になり、並列処理が大幅に改善されました。 Transformerの登場は、シーケンス変換の分野に大きな革新をもたらしました。特に、機械翻訳のタスクでは、従来の最先端モデルを短期間で超える成果を上げ、その後の自然言語処理(NLP)研究の新たな基盤となりました。
Transformerのモデルアーキテクチャ
Transformerは、自然言語処理のための新しいタイプのモデルです。このモデルは、リカレントや畳み込みのような従来の方法を使わず、自己注意機構(Self-Attention)とフィードフォワード層(Feed-Forward Layers)を中心に設計されています。ここでは、Transformerの全体的な構造について簡単に説明します。
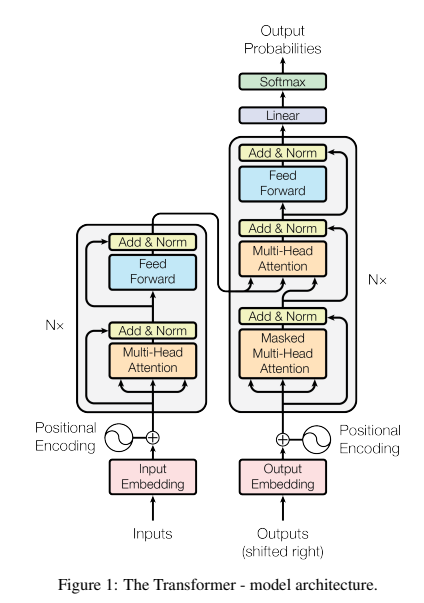
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin,”Attention Is All You Need”, 3P,Figure 1
この図は、Transformerモデルのアーキテクチャを示しています。Transformerは自然言語処理における画期的なモデルであり、自己注意機構とフィードフォワードネットワークを組み合わせた構造を持ちます。この図には、エンコーダとデコーダという二つの主要な構造が描かれており、各部分がどのように相互作用しているかを示しています。
エンコーダ部分(左側)
図の左側はエンコーダ部分です。エンコーダは、入力シーケンスを処理し、その意味的な特徴を抽出します。
Input Embedding: 最初に、入力シーケンスは「Input Embedding」によって数値ベクトルに変換されます。各単語が固定長のベクトルに変換されることで、モデルが処理しやすくなります。
Positional Encoding: 埋め込まれたベクトルには、位置エンコーディングが加えられます。これは、シーケンス内の各単語の位置情報を加えるもので、Transformerがトークンの順序を学習するのを助けます。
Multi-Head Attention: 次に、Multi-Head Attention機構が適用されます。これにより、エンコーダは各単語が他のどの単語に注意を払うべきかを学習します。このプロセスにより、文全体の意味が効率的に捉えられます。
Add & Norm: 「Add & Norm」ブロックは、残差接続と正規化を行います。残差接続は、勾配消失の問題を軽減し、学習を安定させるために用いられます。
Feed Forward: 次に、フィードフォワードネットワークが各トークンに適用され、情報がさらに精製されます。これは通常2層の全結合層から構成され、活性化関数としてReLUを使用します。
デコーダ部分(右側)
図の右側はデコーダ部分です。デコーダは、エンコーダから得られた情報を使って、シーケンスを生成します。
Output Embedding: デコーダも、まずは「Output Embedding」によって入力をベクトルに変換します。この入力は、前のステップで生成されたトークンになります。
Positional Encoding: 出力にも位置エンコーディングが加算されます。これにより、シーケンス内の順序情報がモデルに提供されます。
Masked Multi-Head Attention: 次に「Masked Multi-Head Attention」が適用されます。ここでは、次の単語を予測する際に、将来の単語を見えないようにするためのマスクが適用されます。このマスクにより、モデルは順序を守りながら次のトークンを生成できます。
Multi-Head Attention: デコーダには、エンコーダからの出力に基づいて注意を払う別の多頭注意機構があります。これにより、入力シーケンスと出力シーケンスの関連付けが学習されます。
Add & Norm: これもエンコーダと同様に、残差接続と正規化が行われ、安定した学習が可能になります。
Feed Forward: フィードフォワードネットワークが各トークンに適用され、最終的な特徴抽出が行われます。
出力プロセス
デコーダの最後には、LinearとSoftmax関数が配置されています。
Linear & Softmax: 最終的な出力は線形変換を通し、ソフトマックス関数によって各語彙の出現確率が計算されます。この確率に基づいて、次の単語が選ばれます。これにより、Transformerは一連のトークンを順次生成することができます。
全体の流れ エンコーダとデコーダが協力することで、Transformerは入力シーケンスから出力シーケンスを生成します。エンコーダは入力の特徴を抽出し、デコーダはその特徴をもとに出力を生成します。この一連の処理により、Transformerは翻訳などの複雑な自然言語処理タスクを高い精度で実現しています。
Encoder and Decoder Stacks
Transformerのエンコーダーとデコーダーは、複数の層を積み重ねたスタック構造でできています。それぞれの層は自己注意機構とフィードフォワードネットワークを持ち、情報を効果的に学習する役割を果たします。
エンコーダースタック
エンコーダーは、入力シーケンスを内部表現に変換します。エンコーダーは6つの同じ構造の層を積み重ねた形で構成されていて、各層には2つのサブレイヤーがあります。一つ目は「マルチヘッド自己注意機構」で、シーケンス内の各位置が他の全ての位置と関連づけられるように情報を取り込みます。二つ目は「フィードフォワードネットワーク」で、各位置に対して独立して適用される全結合層です。各サブレイヤーの出力には、残差接続(Residual Connection)とレイヤー正規化(Layer Normalization)が適用され、モデルが安定して学習できるようにしています。
デコーダースタック
デコーダーは、エンコーダーから受け取った情報を基にして出力を生成します。デコーダーも6つの層を積み重ねた構造で、エンコーダーと似ていますが、追加でEncoder-Decoder Attentionがあります。これにより、デコーダーの各位置がエンコーダーの出力全体に注意を払うことができ、より正確な予測が可能になります。また、デコーダーの自己注意機構は、未来の情報を見ないようにマスクを使い、生成時には過去の情報のみを使うようにしています。
Attention(注意機構)
注意機構(Attention)は、Transformerの中で非常に重要な役割を果たしています。この仕組みによって、モデルは入力全体の中からどの部分に注目するべきかを学習し、重要な情報を効率的に処理します。Transformerでは特に、「スケール化内積注意(Scaled Dot-Product Attention)」と「マルチヘッドアテンション(Multi-Head Attention)」という2つの重要なメカニズムが用いられています。
スケール化内積注意
スケール化内積注意は、クエリ(Query)、キー(Key)、バリュー(Value)の3つの入力を使って計算されます。まず、クエリとキーの内積を計算し、その結果をキーの次元数の平方根で割ります。そして、ソフトマックス関数を使って重みを計算し、その重みを使ってバリューを加重平均します。このプロセスにより、モデルはどの情報が重要かを判断し、その情報を効率的に取り出すことができます。
マルチヘッドアテンション
マルチヘッドアテンションは、複数の注意機構を並行して実行する仕組みです。各注意機構(ヘッド)は異なる視点から情報を取り込み、異なる特徴に注目します。これにより、モデルは多様な情報を同時に学習することが可能になります。
具体的には、クエリ、キー、バリューを複数の「ヘッド」に分割し、それぞれでスケールド・ドットプロダクト注意を計算します。その結果を結合し、最終的に線形変換を行うことで、マルチヘッド注意の出力を得ます。このプロセスにより、モデルはより複雑で多面的な依存関係を学習することが可能となります。
注意機構の役割
Transformerにおいて、注意機構はエンコーダーとデコーダーの両方で使用されます。エンコーダーでは、各トークンがシーケンス内の他のトークンにどの程度注意を払うべきかを学習し、情報を効果的に取り込みます。デコーダーでは、生成中のトークンが過去のトークンやエンコーダーの出力に注意を払うことで、より正確な出力を生成しま
この注意機構によって、Transformerは従来のリカレント構造の制約を克服し、シーケンス全体の情報を効率的に処理することができます。これにより、並列処理が可能となり、高速で高精度な学習が実現されているのです。
Position-wise Feed-Forward Networks (位置単位順伝播ネットワーク)
位置単位順伝播ネットワーク(Position-wise Feed-Forward Networks)は、Transformerの各エンコーダー層とデコーダー層で使われる重要な構成要素です。このネットワークは、自己注意機構と組み合わせることで、入力データの各位置の情報を深く理解し、効果的に処理することを助けます。
位置単位順伝播ネットワークの構造
各エンコーダー層とデコーダー層には、自己注意機構の後に位置単位順伝播ネットワークが配置されています。このネットワークは2つの全結合層(Fully Connected Layer)で構成されています。まず1つ目の層で入力を処理し、その後、ReLUという活性化関数を適用します。次にもう1つの層を通して最終的な出力を得ます。
位置単位順伝播ネットワークの役割
このネットワークの役割は、自己注意機構で統合された情報を各トークンに変換し、その特徴を強化することです。これによって、モデルはより豊かで複雑な表現を学習できます。自己注意機構でトークン間の関係を学習した後、フィードフォワードネットワークで各トークンの個別の特徴を強化することで、モデルの精度を向上させています。
並列処理の利点
位置単位順伝播ネットワークは、各トークンを独立に処理するため、並列処理が可能です。この特性により、Transformerは従来のリカレントネットワークよりもはるかに高速に動作し、トレーニングや推論の速度が向上します。位置単位順伝播ネットワークは、自己注意機構と共に、Transformerの高い性能を支える重要な要素です。
Embeddings and Softmax
Transformerモデルにおいて、EmbeddingとSoftmaxは、入力データの表現と出力生成において重要な役割を果たします。これらは、自然言語のトークンを数値形式に変換し、言語を生成する際の確率を計算するために使われます。
Embeddingの役割
Embeddingは、単語やトークンを数値ベクトルとして表現することです。Transformerでは、入力トークンを数値ベクトルに変換するために埋め込み層が使われます。これにより、モデルはトークン間の意味的な関係性を学習できます。意味が似ている単語は、埋め込み空間で近い位置に配置されます。
埋め込みに加えて、位置エンコーディング(Positional Encoding)も使われます。これにより、モデルはシーケンス内で各トークンがどこに位置しているかを把握でき、順序情報を学習します。
Softmaxの役割
Softmaxは、Transformerの出力層で使用される活性化関数です。モデルが出力を生成する際、最後にSoftmax関数を使って各単語が次に来る確率を計算します。この確率分布を基に次にどの単語を選ぶかが決まります。
EmbeddingとSoftmaxの重要性
Embeddingは、トークンをモデルが理解できる数値ベクトルに変換し、文の意味やトークン間の関係を学習する基礎を作ります。一方、Softmaxは次に出力する単語を確率的に決定し、文章の自然さを担います。このように、EmbeddingとSoftmaxはTransformerの性能を支える基本的な要素です。
Positional Encoding (位置エンコーディング)
Transformerは自己注意機構を使ってシーケンス全体を処理しますが、この仕組みだけではモデルはトークンの順序情報を学習することはできません。そこで、シーケンス内のトークンの位置関係を理解するために「位置エンコーディング(Positional Encoding)」が導入されています。
位置エンコーディングの役割
位置エンコーディングは、入力データに順序情報を追加することで、モデルが各トークンの位置を把握できるようにする役割を果たします。これにより、モデルはトークンの意味とその順序を同時に学習し、シーケンス全体の文脈を理解することができます。位置エンコーディングは、入力の埋め込みベクトルに加算されます。
位置エンコーディングの計算方法
位置エンコーディングはサイン波(sin)とコサイン波(cos)を使って計算されます。トークンの位置と埋め込みの次元に基づいて異なる周波数のサイン波とコサイン波を使用することで、各トークンにユニークなエンコーディングが与えられます。この方法により、モデルはトークンの位置関係を学習することができます。
位置エンコーディングの特徴と利点
位置エンコーディングの大きな特徴は、トークン間の相対的な距離を保ちながら計算される点です。これにより、シーケンス内のトークン間の関係をモデルが学びやすくなります。また、位置エンコーディングは固定的で計算が軽いため、長いシーケンスにも対応しやすく、モデルがシーケンス全体の構造を理解するのに役立ちます。
位置エンコーディングの重要性
位置エンコーディングは、Transformerがトークンの順序を理解するために欠かせない要素です。自己注意機構だけではトークンの順序情報が考慮されにくいため、位置エンコーディングを加えることで各トークンの位置情報をモデルに伝え、文脈に基づいたより適切な予測を行えるようにします。 埋め込みベクトルと位置エンコーディングは、Transformerが入力を豊かに表現し、高い性能を発揮するための重要な要素です。
Why Self-Attention
自己注意機構(Self-Attention)は、Transformerがシーケンスを効率的に処理するために使う重要な仕組みです。従来のRNNやCNNと比べて、特に長距離の依存関係の処理や計算効率の面で優れています。
長距離依存関係の処理
RNNはシーケンスを一つずつ処理するため、シーケンスが長くなると離れたトークン同士の関係を学ぶのが難しくなります。自己注意機構は、シーケンス内のすべてのトークンが同時に他のトークンに注意を向けることができるので、遠く離れたトークンの関係も効果的に学習できます。これにより、文章中の遠く離れた単語同士の関係を正確に捉えることができます。
並列化による効率的な学習
RNNは逐次的に処理するため、並列化が難しく学習に時間がかかります。一方、自己注意は全てのトークンを同時に処理できるため、並列処理が可能です。これにより、TransformerはRNNに比べて学習速度が大幅に向上し、大規模なデータセットにも対応しやすくなっています。
計算コストと性能のバランス
自己注意は、シーケンスが短い場合に特に効率が良く、RNNよりも高い性能を示します。シーケンスが長くなると計算コストは増えますが、自己注意はGPUなどのハードウェアに適しているため、大規模な計算も効率的に処理できます。
自己注意と従来手法の比較
RNNと比較して: 自己注意は並列処理が可能で、トレーニングが高速です。また、長距離の依存関係も効果的に捉えることができます。 CNNと比較して: CNNも並列処理ができますが、長距離依存関係の学習には多くの層が必要です。自己注意はすべてのトークン間で直接関係を学習できるため、少ない計算で複雑な依存関係を捉えることが可能です。
Results (結果)
Transformerは、その革新的な自己注意メカニズムと高い計算効率によって、自然言語処理の分野で多くの優れた成果を上げています。このセクションでは、Transformerの成果と他の手法との違いについて説明します。
機械翻訳
Transformerが最初に大きな成果を示したのは、機械翻訳の分野です。特に、英語とフランス語の翻訳タスクで、Transformerは従来のRNNやCNNに比べ、より正確で滑らかな翻訳を実現しました。
自然言語処理全般での性能
Transformerは、翻訳以外の自然言語処理タスクでも優れた成果を挙げています。例えば、文章の要約、質問応答、感情分析などのタスクで、他のモデルを上回る性能を示しています。
トレーニング速度の向上
Transformerは並列処理が可能なため、トレーニング速度が大幅に向上しています。従来のRNNはシーケンスを順番に処理する必要があったため時間がかかりましたが、Transformerは全てのトークンを同時に処理できます。
モデルのスケーラビリティ
Transformerはスケーラビリティに優れており、モデルサイズを大きくしても高い性能を維持しやすいです。パラメータを増やすことで、より複雑な言語理解や生成が可能となり、多くの応用に対応できます。
他のモデルとの比較
Transformerは、従来のRNNやCNNと比較して計算効率と性能の両方で優れています。RNNはシーケンスを逐次的に処理するため、長いシーケンスの学習が難しいですが、Transformerは自己注意を使うことで全トークンを一度に処理し、長距離依存関係を効果的に学習します。CNNと比べても、Transformerは少ない層で複雑な依存関係を捉え、自然言語処理の多くのタスクで高い性能を発揮します。
Conclusion (結論)
Transformerは、その革新的な自己注意メカニズムと優れたスケーラビリティによって、自然言語処理の分野に大きな進展をもたらしました。従来のRNNやCNNが抱えていたシーケンス処理の課題を克服し、機械翻訳、質問応答、文章生成など、多くのタスクで優れた性能を発揮しています。
Transformerの強みは、並列処理による効率的なトレーニング、長距離依存関係の学習能力、そして大規模データセットへの対応力です。これらの特性により、機械翻訳や文章生成のみならず、さまざまな自然言語理解タスクで最先端の性能を実現しています。
さらに、Transformerのアーキテクチャは自然言語処理にとどまらず、画像処理や音声処理といった他の分野にも応用されています。この汎用性の高さがTransformerの大きな特徴であり、今後のAIシステムでも中心的な役割を果たすことが期待されています。 総じて、Transformerは自然言語処理の世界を大きく変え、AI研究における新しい基準を打ち立てました。自己注意メカニズムによって長いシーケンス内の情報を効率的に学習でき、多くのタスクで従来のモデルを上回る成果を達成しています。今後も、Transformerに基づく技術はさらに進化し、多くの新しい応用が開発されていくでしょう。それによって、AIは私たちの生活により深く関わり、さまざまな課題を解決する力を持つようになると期待されています。
本論文では、Transformerというモデルの構造、原理、学習方法、そして成果について詳細に解説しました。Transformerは、その革新的な自己注意メカニズムによってシーケンス全体の情報を効率よく捉え、従来のRNNやCNNの限界を克服しました。これにより、機械翻訳、質問応答、文章生成など、様々な自然言語処理タスクで優れた成果を達成しています。また、Transformerの高いスケーラビリティと汎用性によって、画像処理や音声処理など他の分野への応用も進んでおり、AI研究の幅広い分野で中心的な役割を果たしています。
学習プロセスにおいては、並列処理や正則化技術を活用し、大規模データセットを効率的に利用することが可能である点が強みです。また、Transformerを基盤にしたBERTやGPTなどのモデルは、自然言語理解と生成における標準的な技術として広く採用されており、その影響力は非常に大きいものです。これらのモデルは、日常の多くのシナリオで役立っており、AI技術の普及に大きく寄与しています。例えば、私たちが日常的に使用するデジタルアシスタントや、検索エンジンの性能向上にも大きく影響しています。これにより、AIが人々の生活の中でどれほど重要な役割を果たしているのかが理解できます。
また、Transformerのモデルは、他の自然言語処理の手法では難しかった多くの問題を解決してきました。例えば、長い文脈を持つ文章の理解や、様々なタスクでの言語の生成において高い性能を発揮し、従来のモデルの限界を乗り越える力を見せています。このように、Transformerはただのツールではなく、自然言語処理の分野における革新そのものであると言えます。