
このコラムの趣旨
文化庁の令和5年度著作権セミナーを見て、なぜAI開発が著作権法30条の4の非享受利用に該当するのかの説明不足だったと感じましたので、過去の資料を参考にしつつ、30条の4と機械学習の関係を整理してみました。
今回のコラムでは、AI開発のための機械学習の用途に限定して情報解析を扱い、著作権法30条の4をまとめます。より包括的な著作権法30条の4の解説も後に挙げたいと思います。
また、このコラムではAI開発の中でも、画像生成AIの開発を前提として考えています。
筆者は法律の専門家ではありませんが、今までに提示された政府などの資料に基づき、このコラムを書いていきたいと思います。
※追記:機械学習の過程でデータセットの加工は翻案と記載しましたが
文化審議会著作権分科会法制度小委員会「AIと著作権に関する論点整理について」で複製だと明言されたので複製と訂正していたしました。
柔軟な権利制限規定
著作権法30条の4は、デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定の整備として新設されました。
情報技術革新を背景にIoT・ビッグデータ・AI等に関する技術の活用によって発生するイノベーションの創出が期待されました
しかし、著作物の利用には著作者の許諾が必要であり、著作物の利用ニーズに対応することが困難です。
そのためこのような環境に対応するため柔軟な権利制限規定の整備が求められてきました。
(イノベーション促進に向けた権利制限規定等の検討)
・著作権法における柔軟性のある権利制限規定について、文化審議会著作権分科会報告書(2017 年4月)を受け、明確性と柔軟性の適切なバランスを備えた複数の規定の組合せによる「多層的」な対応について、それぞれ適切な柔軟性を確保した規定の整備を行うため、「推進計画 2016」を踏まえ、速やかな法案提出に向けて、必要な措置を講ずる。また、ガイドラインの策定、著作権に関する普及・啓発、及びライセンシング環境の整備促進などの必要な措置を講ずる。(短期・中期)(文部科学省)
知 的 財 産 戦 略 本 部「知的財産推進計画2017」
そこで提案されたのは、明確性と柔軟性のバランスを適切に備えた「多層的」な対応です。具体的には、行為が権利者の利益に与える影響に基づいて3つの層に分け、各層に対して適切な規定を設けることが提案されました。
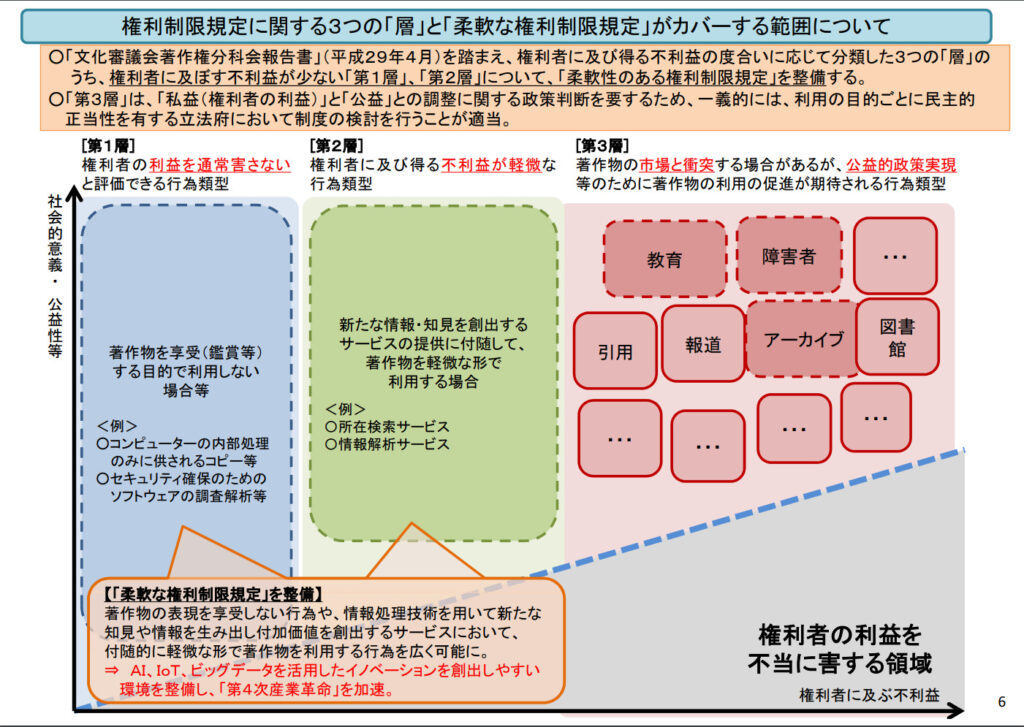
第1層:権利者の利益を通常害さないと評価できる行為類型
第2層:権利者に及び得る不利益が軽微な行為類型
第3層:著作物の市場と衝突する場合があるが、公益的政策実現等のために著作物の利用の促進が期待される行為類型
この中で「第1層」は著作物を鑑賞目的ではない非享受利用目的で活用することで、著作者の利益を損なうことが無い行為を権利制限対象としました。
30条の4 著作物に表現された思想又は感情の享受を目的としない利用の条文について
著作権法30条の4とは何か
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
著作物に表現された思想又は感情の享受を目的としない利用
著作権法30条の4の条文は次の4つに分解できます。
①著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合
②その必要と認められる限度において
③いずれの方法によるかを問わず、利用することができる
④ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
これらについて1つずつ見ていきます
著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合について
「享受」とは「 与えられた、ある物事を受けおさめること。多く精神的、物質的な利益を受けて、それを味わい楽しむことにいう。」
精選版 日本国語大辞典
法第30条の4の「享受」とは、著作物の視聴等を通じて、視聴者等の知的・精神的欲求を満たすという効用を得ることに向けられた行為をいいます。
令和5年度 著作権セミナー「A I と著作権」文化庁著作権課
通常、著作物を視聴などしている視聴者は著作物から知的・精神的欲求を満たす行為に対して、著作者に経済的利益のための対価を支払うことになります。
ただし、非享受利用目的であれば、視聴者は著作物から知的・精神的欲求を満たす行為をしていないため、著作者の許諾なしで行われたとしても著作者の経済的利益を損なうことはありません。
そのため、著作物に表現された思想又は感情の享受を目的としない利用に関しては、原則として著作者からの許諾は必要ありません。
30条の4では、「享受」を目的としない利用行為に対して適用される条文であり、一方で「享受」を目的とする利用行為に対しては適用されません。
また、利用目的が複数あり、「享受」を目的としない行為があっても、「享受」を目的とする行為が併存する場合、本条は適用されません。
なぜAI開発のための著作物の利用が非享受利用目的なのかについては、後述の「なぜAI開発は非享受利用なのか」で詳しく触れます。
この享受目的について1つ触れて置くべき具体例があります。
例えば、3DCG映像作成のため風景写真から必要な情報を抽出する場合で
文化審議会著作権分科会(第68回)、参考資料4、「AIと著作権の関係等について」
あって、元の風景写真の「表現上の本質的な特徴」を感じ取れるような映像の作
成を目的として行う場合は、元の風景写真を享受することも目的に含まれている
と考えられることから、このような情報抽出のために著作物を利用する行為は、本
条の対象とならないと考えられる。
ここに書かれている「表現上の本質的な特徴」とは類似性を判断する際に用いられます。
「江差追分事件」や「アンコウ行灯事件」などの判旨を見るに、既存著作物と一致する部分が絵柄・ポーズ・構図のような具体的な表現でないアイデアだった場合には「表現上の本質的な特徴」には含まれません。
また、「けろけろけろっぴ事件」の判旨から、既存著作物との共通点が創造性の無いありふれた表現の場合でも「表現上の本質的な特徴」には含まれません。
以上のことを踏まえて学習元に使われている既存の著作物に対し「表現上の本質的な特徴」を直接感得できるような生成物を生成することを目的とした画像生成AIを作ることは、享受を目的としてした利用に該当するため本条に適用されないと思います。
この例が何に該当されるかは独自の解釈が強くなりますので、「考察」で改めて触れます。
その必要と認められる限度において
調べても具体的な例が見当たらなかったのでパスします。誰か詳しい人は具体的なことが書かれた資料を添えて教えて下さい
いずれの方法によるかを問わず、利用することができる
この規定により、著作物の複製だけでなく翻案等にも利用できます。これは後述する永岡文科大臣の答弁に裏付けられています。
ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
もっとも議論を生んでいると思いますただし書きです。
この但し書きに該当する場合、権利制限が適用されません。
「著作権者の利益を不当に害すること」ことの判断基準は
当該場合に該当するか否かは,同様のただし書を置いている他の権利制限規定(法第35条第1項等)と同様に,著作権者の著作物の利用市場と衝突するか,あるいは将来における著作物の潜在的市場を阻害するかという観点から判断されることになる。
(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方(著作権法第30条の4,第47条の4及び第47条の5関係)、令和元年10月24日 文化庁著作権課)
現在この但し書きに該当する例として、情報解析用に販売しているデータベースの著作物をAIの学習のために複製する行為があります。
現在判明されている但し書きの該当例はこれだけであり、それ以外について文化庁は最終的判断を司法にぶん投げています。
政府はこの但し書きの該当例について突き詰めていく方針らしいので、今後、政府の見解と裁判を注視していきましょう。
また文化庁はこの但し書きについて法35条と同様扱いをしています。このことについては独自の解釈が強くなると思いますので考察で詳しく触れます。
情報解析について
情報解析の定義とは
「多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行う」ことをいう。
30条の4の元となった旧47条の7では統計的データしか情報解析が行えませんでした。
しかし、改正後の法30条の4では様々な解析に適用できるように統計データに限定する文を削除し、より広範囲の解析が情報解析に含まれるようになりました。
これによって深層学習(ディープラーニング)にも情報解析が適用されるようになり、AI開発の幅が大きく広がりました。
それでは情報解析の定義を分解して見てみましょう
①多数の著作物その他の大量の情報から
「多数の著作物その他の大量の情報から」と書かれていますが、
それでは、例えば10枚か20枚の少数の画像から学習したLoRaは情報解析の定義に含まれると言えるのでしょうか?
ここで柿沼弁護士のブログを引用します。
(『Midjourney、Stable Diffusion、mimicなどの画像自動生成AIと著作権(その2)』2022/09/21、柿沼太一)
条文をよく読むと、「情報解析」の定義は「多数の著作物その他の大量の情報から」と書いてあります。奥邨先生がわかりやすく解説していますが、このような記載ぶりからすると、「多数の著作物」というのは、あくまで「大量の情報」の一例に過ぎません7。
したがって「多数の著作物」を利用していなくても「大量の情報」を利用していれば「情報解析」に該当することになります。
そして、少数の画像を学習に利用することを考えたときに、「1枚1枚の画像」に着目すると確かに「多数の著作物」には該当しませんが、「当該1枚1枚の画像に含まれる情報(個々の画素の内容、画素の位置関係等)」に着目すれば「大量の情報」に該当することはあり得ると思います。
したがって結論としては、少数画像を学習に利用する場合であっても、著作権法30条の4の「情報解析」に該当し、同法が適用されことはある、ということになります。
つまり、たった1枚の画像にすらそこには大量の情報が含まれるているので、少数の画像から学習した場合でも30条の4は適用されると思います。
残り一気にやりましょう
②当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。
「その他の」という言葉が2つ出てきますよね
「その他の」というワードは法律用語で包括的例示と言います。
ここではあくまで「その他の要素に係る情報」、「その他の解析」が重要であって、その直前の「言語、音、影像」や「比較、分類」はあくまで「その他の~」に含まれる例示にすぎません。
つまり多数の著作物その他の大量の情報の要素に係る情報ならなんだっていいのです。「言語、音、影像」には限りません。またそのための抽出した情報の解析なら何でもよく「比較、分類」に限定されません。
日本は機械学習パラダイス!?
条文の権利制限規定さえ満たせば原則として著作者の許諾無しに機械学習が可能です。諸外国に対して、日本が「機械学習パラダイス」と言われるゆえんです。
それでは具体的に何が合法なのか見ていきましょう。
まずAIによる情報解析についての我が国の法制度(著作権法)について確認したところ、我が国において、非営利目的であろうと、営利目的であろうと、複製以外の行為であろうと、違法サイトなどから取得したコンテンツであろうと、方法を問わず情報解析のための作品利用はできると永岡大臣が明言しました。
きいたかしブログ『決算行政監視委員会分科会質疑を振り返る。』2023/4/24
実際にきいちゃんねるで決算行政監視委員会第二分科会の状況を動画にして収めているので載せておきます
30条の4は非享受利用であれば、研究目的かどうか営利目的かどうかは一切関係無く著作者の許諾無しに使用しても合法になります。
これが30条の4が非営利目的・営利目的を問わないということです。
次に複製以外の行為ですが、これは前述した法30条の4の「いずれの方法によるかを問わず、利用することができる」という文の裏付けです。これで後述しますが既存の著作物の複製・翻案というAI開発のためのプロセスが可能になりますし、公衆送信もできます。
一番衝撃的な発言である違法サイトなどから取得したコンテンツでも学習に利用できることですが
動画内でそこの部分の永岡文科大臣の発言を文字にしました。
違法サイトなどから取得したコンテンツですが、違法にアップロードされました著作物が利用できる状況、状態は問題でありまして、違法アップロード行為につきましては、著作権の侵害として損害賠償請求、差止め請求や、刑事罰を受けることとなります。
他方で、インターネット上の著作物を情報解析に用いる場合、大量に収集される著作物がそれぞれ適法なものであるかどうかを確認することは現実的に難しく、これを要件としてしまいますと、ビッグデータを用いた情報解析が困難になる実態が考えられます。
決算行政監視委員会第二分科会での永岡文科大臣の発言
つまり、スクレイピングなどで収集したデータが適法のものか違法アップロードなのかが確認することが困難であることが理由として上がっています。
そのため政府は違法サイトからの学習を推奨しているわけではありません。合法だからといって、違法サイトのデータから学習はやめましょうね。別に政府は否定しているわけでもなく、それどころか「違法サイトなどから取得したコンテンツ」って明言しているような気がしますが
第213回国会 決算行政監視委員会第二分科会 第1号(令和6年5月13日(月曜日))

開発と利用は適用条文が異なる
ここまでAI開発に使われる30条の4の話をしてきましたが、
「AI開発・学習段階」と「生成・利用段階」では、行われている著作
(令和5年度 著作権セミナー「A I と著作権」文化庁著作権課)
物の利用行為が異なり、関係する著作権法の条文も異なります。
そのため、両者は分けて考える必要があります。
当然ですが画像の生成は情報解析とは呼びません。そのため画像生成AIによる生成目的では30条の4は適用されません。
学習とその利用では適用条文が異なります。
30条の4は非享受利用目的限定ですがそれは学習段階であり、生成段階では画像を鑑賞など自分が享受する目的のために画像を生成しても構わないですし、それを公開・販売して他人を享受させるためにAIイラストを生成しても構いません
30条の4の但し書きも生成の段階では関係ありません。生成したAIイラストが著作権者の著作物の利用市場と衝突したり,将来の著作物の潜在的市場を阻害し著作権者の利益を不当に害したとしても生成段階は30条の4とは無関係ですので、何も問題ありません。
なぜAI開発は非享受利用なのか
AI開発が非享受利用の理由
ここからが本題で、サブタイトルの回収です。
それではなぜAI開発は非享受利用目的なのでしょう。
それは人間は著作物に表現された思想又は感情を享受しますが、AIは思想又は感情を享受しないからです。つまり、AIに読み込ませるために学習用データをデータベースに複製しても、AIは思想又は感情を享受しないので、AI開発目的は非享受利用扱いですから権利制限規定が適用されます
それでは今後AGIのようなAIが誕生して、AIが人間のように著作物から思想や感情を享受し始めたら、30条の4適用外になるのでしょうか?
その答えとして「享受」という用語が法律上では人間に限定されるため、仮に「享受」するAIが生まれても法律用語の定義が変わらない限り「享受では無い、非享受利用」として30条の4が適用されます。
このへんは(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方(著作権法第30条の4,第47条の4及び第47条の5関係)、令和元年10月24日 文化庁著作権課)の問11に詳しく書かれています。
AI開発のプロセス
AI開発の流れ図

データ収集・データセット
(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方(著作権法第30条の4,第47条の4及び第47条の5関係)、令和元年10月24日 文化庁著作権課)の問10の例を見てもらえると分かる通り
AI開発のための学習データを収集する行為、またはAI開発を行う第三者に学習用データを提供する行為は著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない利用方法としています。
つまり、データ収集の段階から法30条の4は適用されます。ネット上のデータをダウンロードする行為は法律上複製に該当します。私的使用の範囲を超えたこの行為は本来なら複製権侵害になりますが、非享受利用目的なので権利制限対象です。
また、著作権30条の私的使用ではなく、法30条の4の非享受利用目的なので違法にアップロードされた著作物をダウンロードしても違法ダウンロードにはなりません。前述の永岡文科大臣の発言もあります。
収集したデータをPCなどに読み込ませ、データセットを作る行為も法律上複製に当たります。
学習用データセット作成
データの集合であるデータセットに情報を付加したり、学習に適した形にデータを加工する作業が入ります。学習データセットの作成の段階です。このデータの加工も法律上複製に当たります。
機械学習・深層学習
ついに本番である学習の段階、機械学習・深層学習です。
学習用プログラムとは学習データセットから画像の特徴など規則を見出し、その規則をパラメータとして表現するモデルを作成するために実行されるプログラムのことです。
機械学習・深層学習を行い学習済みモデルを作成します。この作業は法律上著作物の利用では無いです。学習用データセットは著作物を利用していますが、学習によって作成された学習済みモデルは学習済みパラメータという全くの別物になっているので学習用データセットの「複製」でも「翻案」にも当たりません。
学習済みモデル
学習済みモデルには学習用データセットの学習によって作成された学習済みパラメータが含まれています。この学習済みパラメータは数値の羅列であり、入力したデータや学習用データセットの痕跡すら残っていないです。生成物を生成するときにこの学習済みモデルを用います。
この学習済みモデルには著作権があるかどうかはV. 考察で取り扱います。
「無断学習」という言葉が根本的に間違っている理由
さて、ここで世に広がっている「無断学習」という誤った単語を否定します。
無断学習という単語がネット上だけではなく新聞の記事のタイトルでも見るようになりました。
AIの無断学習、日本の著作権法ではOK 侵害にあたるケースは
生成AIの無断学習に広がる困惑 創作者への還元に知恵を


しかし、機械学習・深層学習の項目で触れた通り、法30条の4により著作権者に無許諾で著作物の利用を行っているのは学習データセット作成の段階までです。
前述の通り学習段階では著作物の利用が行われていないため、権利制限規定は関係無く、著作者の許諾は必要ありません。
機械学習・深層学習では法30条の4が無くても著作者の許諾は不要なので「無断学習」という単語は根本的に間違っています。
考察
この項目は外部資料よりも自分の主観が強い考察の項目ですので読み飛ばしてもらってかまわないです。
30条の4と35条但し書き「著作権者の利益を不当に害すること」の共通点
前述の通り30条の4の但し書き「著作権者の利益を不当に害すること」について、文化庁の見解では法35条と同様扱いを受けていますので、法35条についても載せて置きます。
第三十五条 学校その他の教育機関(営利を目的として設置されているものを除く。)において教育を担任する者及び授業を受ける者は、その授業の過程における利用に供することを目的とする場合には、その必要と認められる限度において、公表された著作物を複製し、若しくは公衆送信(自動公衆送信の場合にあつては、送信可能化を含む。以下この条において同じ。)を行い、又は公表された著作物であつて公衆送信されるものを受信装置を用いて公に伝達することができる。ただし、当該著作物の種類及び用途並びに当該複製の部数及び当該複製、公衆送信又は伝達の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
2 前項の規定により公衆送信を行う場合には、同項の教育機関を設置する者は、相当な額の補償金を著作権者に支払わなければならない。
3 前項の規定は、公表された著作物について、第一項の教育機関における授業の過程において、当該授業を直接受ける者に対して当該著作物をその原作品若しくは複製物を提供し、若しくは提示して利用する場合又は当該著作物を第三十八条第一項の規定により上演し、演奏し、上映し、若しくは口述して利用する場合において、当該授業が行われる場所以外の場所において当該授業を同時に受ける者に対して公衆送信を行うときには、適用しない。
学校その他の教育機関における複製等
ただし、当該著作物の種類及び用途並びに当該複製の部数及び当該複製、公衆送信又は伝達の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
この部分が法30条の4と類似しており、同じ但し書きに著作権者の利益を不当に害することについて書かれています。
法35条は法30条の4とは違い文化庁が「著作権者の利益を不当に害すること」の具体的例を様々なケースに当てはめて提示しています。>改正著作権法第35条運用指針(令和 2(2020)年度版)著作物の教育利用に関する関係者フォーラム
「著作権者の利益を不当に害すること」という但し書きは
著作者が利益を不当に害していると主張すれば、学習に使われない日本版オプトアウト制度と解釈する人もいますが
同様扱いである35条を考慮にいれてもそれは全くと言って間違っています。
35条の「著作権者の利益を不当に害すること」という但し書きについて、法30条の4で語ったのと同様、当該著作物の種類及び用途並びに当該複製の部数及び当該複製、公衆送信又は伝達の態様に照らし、これに該当するかどうかは著作権者の利用市場と潜在市場を考慮します。
改正著作権法第35条運用指針(令和 2(2020)年度版)著作物の教育利用に関する関係者フォーラムには様々な「著作権者の利益を不当に害すること」のケースが載っていますが、著作権者の主張で教育機関の著作物の複製を止めてもらえるといった例が1つも無いこともそれを裏付けられます。
「表現上の本質的な特徴」を直接感得できる生成目的
もう一度、該当項目を引用します
例えば、3DCG映像作成のため風景写真から必要な情報を抽出する場合で
文化審議会著作権分科会(第68回)、参考資料4、「AIと著作権の関係等について」
あって、元の風景写真の「表現上の本質的な特徴」を感じ取れるような映像の作
成を目的として行う場合は、元の風景写真を享受することも目的に含まれている
と考えられることから、このような情報抽出のために著作物を利用する行為は、本
条の対象とならないと考えられる。
例に出ている風景写真から必要な情報を抽出する3DCG映像作成以外何が該当するのか考えて見ました。
自分が考えた中ではわざと学習元の複製・翻案装置として、学習元の鑑賞機械にするために過学習モデルを作ることがこれに該当するのではないかと考察しました。
ただ過学習モデルを作る目的では当然該当しないと思います。あくまで享受が目的の過学習モデルを作ることです。
さてここでキャラクター再現LoRaや画風再現LoRaはこれに該当するのか考察します。
文化庁作成の資料「AIと著作権の関係等について」でこの話題が出てきた時の柿沼弁護士のツイートです。


柿沼弁護士の意見では特定のキャラクターを学習し再現するLoRaもこれに該当するのではと疑問を投げかけています。
また柿沼弁護士のブログの記事にて
この論点は「情報解析に際して、情報解析の対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物の作成目的(=対象著作物の享受目的)が併存している場合、対象著作物の利用行為は30条の4の対象になるか」という問題ですから、LoRAなどの技術を利用し「対象著作物の作風の再現を目的として行う利用行為」の場合は、「享受目的はない」ということになると思われます。
「生成AIと著作権侵害」の論点についてとことん検討してみる,2023/07/03,柿沼太一
ただし、学習段階において「作風の再現を目的とする」と「表現の本質的な特徴の再現を目的とする」を区別することは相当難しいでしょうね(だからこそ、学習段階における享受目的の認定には慎重に、と繰り返し強調しているところです)。
キャラクターと作風は著作権法上の共通点はどちらもアイデアであり著作物では無いが、アイデアと「表現の本質的な特徴」の境界があいまいなところがあります。
キャラクター自体はアイデアであり抽象的概念なので著作物ではありませんが、アイデアであるキャラクターを具体的に作品に表現したキャラクターデザインなどは著作物として扱われます。
しかし、キャラクターのアイデアと「表現の本質的な特徴」の境界は曖昧なところがあります。
例えばドラえもんは「ポケットの付いた青たぬき」と言えますが、これは藤子・F・不二雄先生のアイデアにすぎないので著作権はありません。ただし、ドラえもんを漫画のコマなどに具体的表現として描けば著作権が発生します
「ポケットの付いた青たぬき」というアイデアを描けばすべてドラえもんの著作権侵害になるのでしょうか?アイデアと「表現の本質的な特徴」との違いは曖昧です。
次に作風です。
著作物でないもの(単なるデータ(事実)やありふれた表現、表現でないアイディア
令和5年度著作権セミナー「AIと著作権」文化庁著作権課
(作風・画風など))は、著作権法による保護の対象には含まれません。
「創作的表現」が共通していることが必要であり、アイディアなど
令和5年度著作権セミナー「AIと著作権」文化庁著作権課
表現でない部分、又は創作性がない部分が共通するにとどまる
場合は、類似性は否定されます
このように作風は文化庁の著作権法セミナーでも再三著作物性を否定されています。また、「江差追分事件」や「アンコウ行灯事件」などの判旨から「表現上の本質的な特徴」に絵柄・作風などのアイデアは含まれないとされています。
ただし、絵から完全に作風・絵柄だけを切り離すことは不可能です。現実の裁判では作風・絵柄に著作権は無くても、類似性を立証するために作風・絵柄の共通点も含むことがあります。
つまり、絵柄・作風もアイデアと「表現の本質的な特徴」の境界は曖昧なのです。
さて、本題に入ります。
キャラクター再現LoRaや画風再現LoRaを作ることは享受利用目的に該当するのでしょうか?
私ははっきり違うと主張します。
あくまで学習元のイラストの複製・翻案を生成する鑑賞装置を作ることが、学習元を直接享受していると同じなので享受目的に該当します。
しかし、キャラクターや作風など学習元とはかけ離れた、アイデアと「表現の本質的な特徴」の曖昧な表現には該当しないと思います
また、civitaiにあるLoRaはその多くが特定のものを再現をすることを目的としています。キャラクター、人物、背景、構図、小物、衣類、建物など。その中には著作物の再現目的またはアイデアと「表現の本質的な特徴」が曖昧な表現の再現目的が含まれています。LoRaの用途として主にこのような集中した追加学習によって特定のものを再現する目的があります。これらをすべて学習段階から享受目的利用とすれば、それは情報解析の用途を大きく制限することになります。
柿沼弁護士のブログ(「生成AIと著作権侵害」の論点についてとことん検討してみる,2023/07/03,柿沼太一)では度々、安易に享受目的認定はすべきではないことが語られています。あくまで類似性のある生成物が生成されるのは生成段階であり、学習段階でそれを確定し享受認定することは著作物の利用行為を大きく制限してしまい技術開発などが委縮してしまう恐れがあります。
ましてや著作物の類似表現だけでなく、アイデアと「表現の本質的な特徴」の曖昧な表現(キャラクターや作風など)の再現まで享受目的認定されたら画像生成AI開発を大きく制限することになります。
以上から文化庁の見解として例にあげている以上の安易な享受認定は避けるべきだと思います。
学習済みモデルの著作権
3つの理由で学習済みモデルに著作権は無いと思います
1つ目の理由は学習済みモデルはコンピューターの内部処理によって、機械的に生まれたものであり人間の関与によるものでは無いこと
2つ目の理由は学習済みモデルのパラメータは数字の羅列でしか無く創造性が無いこと
これは経産省の資料から引用します。
たとえば、学習済みパラメータは大量の数値データであって、創作性等が認められず、通常は知的財産権(著作権等)の対象にはならない可能性が高いと考えられる
(AI・データの利用に関する契約ガイドライン、平成30年6月経済産業省)
著作物は思想又は感情を創作的に表現したものであって数値の羅列である学習済みモデルは該当しない可能性が高いです。
3つ目の理由は法30条の4の非享受利用目的に反するからです。
著作物は「思想又は感情を創作的に表現したもの」であり、30条の4は「思想又は感情の享受を目的としない利用」。
AI開発「表現」と「享受」は別ですが、学習データセットを機械学習によって作られた学習済みモデルのパラメータが思想感情を創作的に表現した著作物扱いだったら それは学習データから思想感情を享受していることになると思います。
よってAI開発によって生まれた学習済みモデルが思想感情を創作的に表現した扱いでしたら非享受利用の30条の4の目的に反して適用外になってしまいます。
AI開発と著作人格権
著作人格権に触れている人全然いませんよね
第五十条 この款の規定は、著作者人格権に影響を及ぼすものと解釈してはならない。
著作者人格権との関係
「この款の規定」とは著作権制限規定をすべて指します。つまり、30条の4~47条(一部適用外)のことを指し、当然30条の4も含まれます。著作権利制限規定は著作権の制限をする規定であって、著作人格権を制限する規定では無いことを示しています。
ここでは著作人格権の1つである同一性保持権を見ていきます。画像にサインなどが入っている場合氏名表示権なども関係があるかもしれませんが特殊な事例なため割愛します。
AI開発のプロセスで学習データセット作成の過程でデータを付与したり加工する工程が入ると書きました。つまり、著作物の改変をしているわけで同一性保持権侵害にひっかかります。
前述の通り権利制限規定は著作権を制限するものなので、著作人格権は制限されません。
それではAI開発は同一性保持権侵害になってしまうのでしょうか?
ここで1つ判決を見ていきましょう
43条の適用により、他人の著作物を翻訳、編曲、変形、翻案して利用することが認められる場合に他人の著作物を改変して利用することは当然の前提とされているのであるから、著作者人格権の関係でも違法性のないものとすることが前提とされているものと解するのが相当であり、このような場合は、同法20条2項4号所定の「やむを得ないと認められる改変」として同一性保持権を侵害することにはならないものと解するのが相当である。
血液型と性格事件
法30条の4では「いずれの方法によるかを問わず、利用することができる。」と条文に書かれていて、永岡文科大臣の発言によって複製以外も適用されるため「他人の著作物を翻訳、編曲、変形、翻案して利用することが認められる場合に他人の著作物を改変して利用すること」に該当します。
また著作物の改変を目的としているわけではなく、あくまで機械学習のために適した学習データセットに加工することが目的です。
つまり、学習データセット作成のための著作物の加工は同法20条2項4号所定の「やむを得ないと認められる改変」として同一性保持権を侵害することにはならないと思います。
またコンピューター内部処理で完結し、公表されることは無いので著作者の意に反する行為ではないのではと思います。
結論
著作権法の30条の4がAIや機械学習とどのように関連するのかを今回の記事で詳しく解説しました。著作権法は、文化の発展の寄与のために、著作者の権利を保護する一方で、ある特定の目的で著作物を使用することを可能にするという、バランスのとれたものです。しかし、ここで考慮すべきポイントが一つあります。それは、非享受利用目的という概念です。
非享受利用目的とは、著作物の思想又は感情を享受する目的でない利用を指します。AIや機械学習がこの非享受利用目的に該当するという観点から見ると、機械は思想や感情を持たないため、データを読み込むという行為が非享受利用目的となります。
先日開催された文化庁セミナーでも、この点についての説明が不十分であったと感じていました。そこで、過去の資料を参考にしながら、この記事では30条の4とAI開発との関連性について詳細に解説します。
また、最近では機械学習について誤った情報やデマが出回っているという問題もあります。これらのデマは、技術の理解を歪め、誤った判断や予測を招く可能性があります。そのため、我々は一次資料や信頼性の高い情報に基づいて考えることが重要です。誤った情報によって騙されないよう、自身の判断を信じ、自己の思考を深めることが求められます。
本記事でも、掲載した情報や引用元の信頼性を吟味し、自己の判断でその正誤を評価していただくことをお勧めします。この記事が、そのような判断を行うためのきっかけとなれば、とても嬉しく思います。機械学習やAIの発展に対する法的な視点からの理解が深まることを願っています。
参考資料
- 「条解著作権法」(小泉直樹 茶園成樹他、2023/06/05,弘文堂)
- 文化庁:令和5年度著作権セミナー「AIと著作権」(https://www.youtube.com/watch?v=eYkwTKfxyGY&list=PLJpjIHxy0a-yM4qxu1IewZHozm6wTCnvW&index=47)
- 令和元年10月24日文化庁著作権課「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方(著作権法第30条の4,第47条の4及び第47条の5関係)」(https://www.bunka.go.jp/seisaku/chosakuken/hokaisei/h30_hokaisei/pdf/r1406693_17.pdf)
- 文化庁「著作権法の一部を改正する法律 概要説明資料」(https://www.bunka.go.jp/seisaku/chosakuken/hokaisei/h30_hokaisei/pdf/r1406693_02.pdf)
- 文化庁「AIと著作権の関係等について」参考資料4(https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/bunkakai/68/pdf/93906201_09.pdf)
- 平成 30 年 6 月経済産業省「AI・データの利用に関する契約ガイドライン」(https://www.meti.go.jp/policy/mono_info_service/connected_industries/sharing_and_utilization/20180615001-3.pdf)
- STORIA法律事務所(https://storialaw.jp/)