
この記事は次の論文を紹介した記事です。
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever,”Learning Transferable Visual Models From Natural Language Supervision”,

論文の概要
はじめに
近年、自然言語処理(NLP)における大規模な事前学習が大きな成功を収めてきました。本論文では、その成功をコンピュータビジョンの分野に転用し、「自然言語監督から転移可能な視覚モデルを学習する(CLIP)」という新しいアプローチを提案しています。
研究の背景と目的
従来のコンピュータビジョンシステムは、あらかじめ決められたオブジェクトカテゴリを予測するように訓練されていました。しかし、この方法では汎用性に限界があり、新たな視覚概念を指定するには追加のラベル付きデータが必要です。これに対し、画像に関するテキストデータから直接学習することで、より広範な監督信号を活用し、汎用的な視覚モデルを構築することを目指しています。
提案手法: CLIP
CLIP(Contrastive Language-Image Pre-training)は、画像とテキストのペアを使用して学習するマルチモーダルモデルです。このモデルは、4億組の(画像、テキスト)ペアを用いて訓練され、自然言語を使って学習した視覚概念を参照することで、ゼロショットで新しいタスクに適応できます。
モデルアーキテクチャ
画像エンコーダ: ResNet-50をベースに改良されたモデルを使用。
テキストエンコーダ: トランスフォーマーベースのアーキテクチャを採用。
トレーニング方法
CLIPはコントラスト学習を用いて、バッチ内の画像とテキストのペアリングの正確性を予測します。これにより、効率的かつスケーラブルに視覚表現を学習します。
データセット
インターネットから収集した4億組の(画像、テキスト)ペアを使用。これにより、非常に広範な視覚概念をカバーしています。
実験結果
ゼロショット転移
CLIPは、追加の訓練なしで新しいタスクに適応する能力を示しました。例えば、ImageNetデータセットにおいて、1.28百万の訓練例を使用せずにResNet-50と同等の精度を達成しました。
パフォーマンスの効率性
CLIPは、従来の画像キャプションベースラインよりも効率的にゼロショット転移を実現しました。
バイアスと公平性
CLIPは、異なる性別や人種間で分類精度に差が見られました。これらのバイアスを軽減するための研究が今後の課題となります。
分布シフトへのロバスト性: CLIPは、分布シフトに対しても高いロバスト性を示しました。
考察と今後の展望
CLIPは、ゼロショット学習において強力な性能を示し、自然分布シフトに対しても堅牢なモデルです。しかし、データ効率性や学習バイアスなどの課題が残されています。今後の研究では、これらの課題を克服し、CLIPの実用化と改良に向けた方法を探求することが求められます。
Introduction(序論)
背景と動機
近年、自然言語処理(NLP)の分野では、生データのテキストから直接学習する事前学習方法が大きな変革をもたらしています。自己回帰モデルやマスク言語モデルなどのタスク非依存の目的が、計算量やモデル容量、データの多様性を大幅に向上させており、これによりGPT-3のような高度なシステムが登場しました。これらのシステムは、特定のデータセットに特化した訓練データをほとんど必要とせず、多くのタスクで競争力を発揮しています。
研究の目的
本研究の目的は、自然言語を用いた監督学習を視覚モデルに応用することで、コンピュータビジョンの分野においても同様のブレークスルーを実現することです。これにより、従来のラベル付きデータセットに依存することなく、スケーラブルな事前学習方法を目指します。
関連研究
過去20年にわたり、画像に関連するテキストを予測することでコンテンツベースの画像検索を改善する試みが続けられてきました。最近では、CNNを用いたキャプション予測や、画像とテキストのペアを利用したマルチモーダル学習が有望であることが示されています。これらの方法は、多ラベル分類タスクに基づいており、転移タスクにおいても競争力のある性能を発揮しています。
提案手法
本研究では、4億組の(画像、テキスト)ペアから学習したCLIP(Contrastive Language-Image Pre-training)というモデルを提案しています。CLIPは、バッチ内の(画像、テキスト)ペアの正確な一致を予測するシンプルな事前学習タスクを使用して、効率的かつスケーラブルに視覚表現を学習します。
主な貢献
- ゼロショット転移
自然言語を利用して学習された視覚概念を活用し、追加の訓練を必要とせずに新しいタスクに適応可能です。
- パフォーマンスの向上
ImageNetデータセットにおいて、1.28百万の訓練例を使用せずにResNet-50と同等の精度を達成しました。
- 汎用性の証明
OCR、アクション認識、地理位置特定、細分類など、様々なタスクで競争力のある性能を示しています。
このように、序論では本研究の背景、目的、関連研究、提案手法について詳述されています。具体的な実験結果や考察は後続のセクションで取り上げられています。
Contrastive Pre-training(コントラスト学習による事前学習)
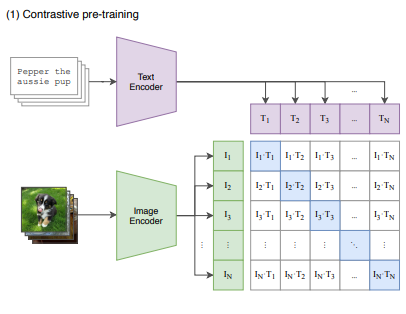
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever,”Learning Transferable Visual Models From Natural Language Supervision”, 2P,figure1,(1) Contrastive pre-training
この図は、CLIP(Contrastive Language-Image Pre-training)モデルのコントラスト学習による事前学習の仕組みを示しています。以下に、この図の各要素について詳しく解説します。
- 入力データ
- 「Pepper the aussie pup」は、テキストデータの例です。
- その下犬の画像が表示されています。これは、画像データの例です。
- エンコーダ
- テキストエンコーダ(Text Encoder)
- テキストデータはテキストエンコーダに入力され、埋め込みベクトル(T1, T2, …, TN)に変換されます。
- 画像エンコーダ(Image Encoder)
- 画像データは画像エンコーダに入力され、埋め込みベクトル(I1, I2, …, IN)に変換されます。
- テキストエンコーダ(Text Encoder)
- 埋め込みベクトルの生成
- テキストエンコーダによって生成されたテキストの埋め込みベクトル(T1, T2, …, TN)は、図の上部に配置されます。
- 画像エンコーダによって生成された画像の埋め込みベクトル(I1, I2, …, IN)は、図の左側に配置されます。
- コントラスト学習
- 生成されたテキストと画像の埋め込みベクトルは、N×Nのマトリックス形式で配置されます。
- このマトリックスの各要素は、対応するテキストと画像のペアのコサイン類似度を表します。
- 例えば、I1とT1のペア、I2とT2のペア、…、INとTNのペアが正しい対応(実際のペア)です。
- コントラスト学習の目的は、これら正しいペアのコサイン類似度を最大化し、誤ったペアのコサイン類似度を最小化することです。
図の流れ
- テキストデータと画像データをそれぞれのエンコーダに入力します。
- テキストエンコーダは、テキストを埋め込みベクトルに変換します。同様に、画像エンコーダは、画像を埋め込みベクトルに変換します。
- 生成されたテキストと画像の埋め込みベクトルをN×Nのマトリックスに配置し、それぞれのペアのコサイン類似度を計算します。
- コントラスト学習を用いて、正しいペアの類似度を最大化し、誤ったペアの類似度を最小化するようにモデルを訓練します。
このプロセスにより、CLIPは多様な視覚概念とその対応するテキストの関係を効率的に学習し、ゼロショット転移性能を向上させます。
Create dataset classifier from label text(ラベルテキストからデータセット分類成する)とUse for zero-shot prediction(ゼロショット予測への利用)
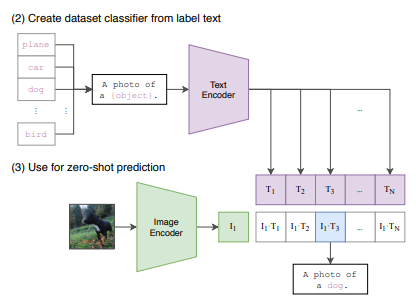
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever,”Learning Transferable Visual Models From Natural Language Supervision”, 2P,figure1,(1) Create dataset classifier from label text,(2) Use for zero-shot prediction
この図は、CLIPモデルがどのようにしてデータセットの分類器を作成し、ゼロショット予測を行うかを示しています。以下に、各セクションの詳細を説明します。
(2) Create dataset classifier from label text(ラベルテキストからデータセット分類器を作成する)
- ラベルテキストの準備
- 左側に「plane」「car」「dog」「bird」などのラベルが示されています。これらはデータセット内のカテゴリです。
- 各ラベルは「A photo of a {object}.」というテンプレートに当てはめられます。例えば、「dog」の場合、「A photo of a dog.」となります。
- テキストエンコーダへの入力
- このテンプレート文はテキストエンコーダに入力されます。
- テキストエンコーダによる埋め込みベクトルの生成
- テキストエンコーダは、各テンプレート文を埋め込みベクトル(T1, T2, …, TN)に変換します。これにより、各カテゴリに対応する埋め込みベクトルが得られます。
(3) Use for zero-shot prediction(ゼロショット予測への利用)
- 画像エンコーダへの入力
- 左側に犬の画像が示されています。この画像は画像エンコーダに入力されます。
- 画像エンコーダによる埋め込みベクトルの生成
- 画像エンコーダは、画像を埋め込みベクトル(I1)に変換します。
- コサイン類似度の計算
- 画像の埋め込みベクトル(I1)は、テキストエンコーダによって生成された各カテゴリの埋め込みベクトル(T1, T2, …, TN)と比較されます。
- 各カテゴリの埋め込みベクトルとのコサイン類似度が計算されます。
- 最も高い類似度のカテゴリを予測
- 画像の埋め込みベクトルと最も高いコサイン類似度を持つテキスト埋め込みベクトルが選ばれ、そのカテゴリが予測結果となります。
- この例では、最も高い類似度を持つテキスト埋め込みベクトルが「A photo of a dog.」であるため、画像は「dog」と予測されます。
図の流れ
- (2) データセット分類器の作成
- ラベルテキストをテンプレート文に変換し、テキストエンコーダに入力して埋め込みベクトルを生成します。
- (3) ゼロショット予測
- 画像を画像エンコーダに入力して埋め込みベクトルを生成し、そのベクトルをテキストエンコーダによるカテゴリ埋め込みベクトルと比較します。
- 最も高いコサイン類似度を持つカテゴリが予測結果として選ばれます。
このプロセスにより、CLIPは追加の訓練なしで新しいタスクに適応し、画像のゼロショット分類を実現します。
Related Work(関連研究)
1. 自然言語による監督の利用
自然言語を訓練信号として利用するモデルは、広範な領域にわたる研究をカバーしています。代表的な研究には以下のものがあります。
- トピックモデル(Blei et al., 2003)
- 単語、文、段落ベクトル(Mikolov et al., 2013; Kiros et al., 2015; Le & Mikolov, 2014)
- 言語モデル(Bengio et al., 2003)
これらの研究は、分布的意味論や自然言語処理全般において、自然言語を監督信号として利用しており、CLIPの基盤となる考え方です。
2. ウェブによる監督学習
CLIPに関連するアイデアとして、ウェブによる監督学習があります。これは、画像検索エンジンを使用して画像データセットを構築し、検索クエリをラベルとして利用する手法です(Fergus et al., 2005)。大規模でノイズの多いラベル付きデータセットで訓練された分類器が、小規模で精密にラベル付けされたデータセットで訓練されたものに匹敵する性能を示すことがあります。
3. マルチモーダルモデルの学習
最近の研究では、視覚と言語の結合モデルの学習が活発に行われています。この分野の研究は、視覚質問応答や視覚的常識推論、マルチモーダル含意などの複雑な下流タスクを解決するために、視覚と言語を豊かに結びつけることを目的としています。これらのアプローチは、以下のように複数の事前学習済みサブシステムを組み合わせたモデルを利用しています。
- 画像特徴モデル
- 領域提案/物体検出モデル
- 事前学習済みのマスク言語モデル(BERTなど)
これに対して、CLIPは自然言語の監督を通じて視覚モデルをゼロから学習することに焦点を当てており、視覚と言語の結合は単一の内積による共同埋め込み空間で行われます。
4. データセットとフィルタリング
現代の画像テキスト検索の研究は、Pascal1K、Flickr8K、Flickr30Kなどのクラウドソースの画像キャプション評価データセットに依存しています。しかし、これらのデータセットは相対的に小さく、性能に限界があります。自動的により大きなデータセットを作成する方法として、Conceptual Captions、LAIT、OCR-CCなどが提案されています。これらのデータセットは特定のタスクに対して設計されているため、CLIPで使用されるWITデータセットよりも小規模です。
5. その他の研究
CLIPの前提となる研究として、視覚と自然言語の結合に関する先行研究があります。これには、初期の画像検索やオブジェクト分類における自然言語説明の利用が含まれます。また、音声やビデオの分野でも大規模な自然言語監督を利用した研究が進行中です。
CLIP(Contrastive Language-Image Pre-training)
1. モデルアーキテクチャ
CLIPは、画像エンコーダとテキストエンコーダを用いて、画像とテキストの埋め込み空間を学習するマルチモーダルモデルです。以下がその主な構成要素です。
- 画像エンコーダ: ResNet-50を基本とし、いくつかの改善を加えています。具体的には、ResNet-Dの改良やアンチエイリアス処理、グローバル平均プーリング層の代わりにアテンションプーリング機構を導入しています。
- テキストエンコーダ: トランスフォーマーベースのアーキテクチャを使用し、テキストの埋め込みを生成します。
2. トレーニング手法
CLIPは、コントラスト学習を利用して画像とテキストのペアリングの正確性を予測します。
- コントラスト学習: バッチ内の画像とテキストのペアが実際に対応しているかどうかを予測するタスクです。具体的には、バッチ内の全ての可能なペアのうち、実際のペアのコサイン類似度を最大化し、誤ったペアのコサイン類似度を最小化します。この目的を達成するために、対称的なクロスエントロピー損失を最適化します。
3. データセット
CLIPの訓練には、インターネットから収集された4億組の画像とテキストのペアが使用されます。このデータセットは、幅広い視覚概念をカバーするために設計されています。
- データ収集: 500,000のクエリを使用して、インターネットから画像とテキストのペアを収集します。これにより、多様な視覚概念を含む大規模なデータセットが構築されました。
4. パフォーマンス
CLIPは多くのタスクで競争力のある性能を示しています。特に以下の特性が強調されています。
- ゼロショット転移: 学習後に追加の訓練を行わずに新しいタスクに適応する能力です。例えば、ImageNetデータセットにおいて、CLIPは1.28百万の訓練例を使用せずにResNet-50と同等の精度を達成しました。
- 効率性: CLIPはコントラスト目的を使用することで、従来の画像キャプションベースラインよりも効率的にゼロショット転移を達成しています。
5. 制限事項と今後の課題
CLIPは強力なゼロショット性能を持つ一方で、いくつかの課題も残っています。
- データ効率性: 深層学習モデルのデータ効率性が低いため、CLIPは大量の訓練データを必要とします。今後の研究では、データ効率性を向上させる方法が求められます。
- バイアス: CLIPはインターネットから収集された未フィルタリングのデータに基づいているため、社会的なバイアスを含む可能性があります。
Experiments(実験)
1. Zero-Shot Transfer(ゼロショット転移)
1.1. 動機
ゼロショット学習は、画像分類において未見のオブジェクトカテゴリに一般化する能力を指します。CLIPでは、この能力をより広い意味で使用し、未見のデータセットへの一般化能力を評価しています。これにより、CLIPが新しいタスクを行う能力を測定しています。
1.2. CLIPの使用法
CLIPは、画像とテキストのペアを入力として、事前に学習した埋め込み空間を用いてゼロショット転移を実現します。この方法により、追加の訓練データなしで新しいタスクに適応することが可能です。
2. Representation Learning(表現学習)
2.1. 概要
表現学習の評価方法として、線形分類器を用いてモデルの表現の質を測定します。線形分類器の性能は、事前学習の間に学習された一般的かつロバストな表現の品質を評価するために使用されます。
2.2. アプローチ
CLIPでは、線形分類器を用いて異なるデータセットでの性能を評価します。これにより、表現学習の効果を直接測定し、異なるタスクへの適応能力を比較することができます。
3. Bias and Fairness(バイアスと公平性)
3.1. バイアスの検出
CLIPモデルが異なる性別や人種に対してどのようなバイアスを持っているかを検証します。例えば、FairFaceデータセットを用いた評価で、男性と女性、異なる人種の分類精度に差があるかを調査しました。
3.2. 結果
CLIPは、男性と女性、異なる年齢層、異なる人種間で分類精度に差が見られました。これらのバイアスは、訓練データやモデルの設計による影響を反映している可能性があります。
4. Robustness to Distribution Shift(分布シフトへのロバスト性)
4.1. 分析
CLIPのロバスト性を評価するために、ImageNet関連のデータセットを用いたテストを実施しました。これにより、分布が変わっても性能を維持する能力を測定しました。
4.2. 結果
分布シフトに対して、CLIPは他のモデルに比べて高いロバスト性を示しました。特に、ImageNet-VidやYouTube-BBデータセットで顕著な改善が見られました。
結論
「Experiments」セクションでは、CLIPのゼロショット転移能力、表現学習の品質、バイアスの存在、そして分布シフトに対するロバスト性が詳細に評価されています。これにより、CLIPの全体的な性能とその限界が明確に示されています。
Discussion(考察)
1. ゼロショット学習の強調
1.1. 結果の解釈
CLIPはゼロショット学習において高い性能を示しました。具体的には、様々なデータセットで競争力のある結果を出しており、CLIPが自然言語による監督を通じて多様な視覚概念を学習できることを示しています。
1.2. 効果的ロバスト性
分布シフトに対するロバスト性の評価でも、CLIPは高い性能を示しました。従来のImageNetベースのモデルと比較して、CLIPは自然分布シフトに対しても堅牢であることが分かりました。
2. 制限事項と課題
2.1. データ効率性の問題
深層学習モデルの一般的な課題として、データ効率性が挙げられます。CLIPも例外ではなく、大量のデータを必要とします。例えば、全ての画像を一秒ごとに提示しても、32エポックの訓練には405年かかる計算になります。これに対処するためには、自己監督学習や自己訓練の手法を組み合わせることが有望です。
2.2. バイアスの存在
CLIPはインターネットから収集されたデータに基づいているため、社会的なバイアスを学習する可能性があります。この問題は、以前の画像キャプションモデルでも指摘されており、CLIPでも同様の課題が存在します。
2.3. 複雑なタスクへの適用
自然言語だけで画像分類器を指定することには限界があります。多くの複雑なタスクや視覚的概念はテキストだけで指定するのが難しいです。また、ゼロショットから数ショットへの移行時にパフォーマンスが低下する問題も指摘されています。これに対処するためには、CLIPの強力なゼロショット性能と効率的な数ショット学習を組み合わせる方法の開発が必要です。
3. 今後の研究方向
3.1. 自己監督学習の統合
CLIPのデータ効率性を向上させるために、自己監督学習の手法を統合することが有望です。これにより、より少ないデータで高性能なモデルを構築できる可能性があります。
3.2. 新しいベンチマークの作成
現在の評価データセットは、主に既存の教師ありデータセットを使用しているため、ゼロショット転移能力を評価するための新しいベンチマークの作成が求められます。
3.3. バイアスの軽減
CLIPの学習バイアスを軽減するための戦略も今後の研究で重要です。これには、データのフィルタリングや新しいトレーニング手法の開発が含まれます。
Conclusion(結論)
1. 成果の総括
本研究は、自然言語処理(NLP)におけるタスク非依存の大規模事前学習の成功を、コンピュータビジョンの分野に適用できるかを探求しました。その結果、類似した行動が視覚の分野でも見られることが確認されました。この発見により、視覚モデルにおける自然言語監督の社会的影響についても議論が行われています。
2. CLIPモデルの学習と性能
CLIPモデルは、事前学習を通じて多様なタスクを実行する能力を学習します。これにより、自然言語プロンプトを利用して、多くの既存データセットにゼロショットで転移可能な能力が得られます。十分なスケールであれば、このアプローチの性能はタスク特化型の教師ありモデルと競争力があります。しかし、現時点ではまだ多くの改善の余地があるとされています。
3. 今後の課題と展望
3.1. 計算効率とデータ効率の向上
現在のハードウェアでは、ゼロショットCLIPが最先端の性能に到達するには、計算リソースの1000倍の増加が必要と見積もられています。これを達成するためには、さらなる研究と技術の進歩が必要です。
3.2. タスク学習と転移能力の改善
ゼロショットCLIPの性能は、特定のタスクでまだ弱いことがセクション3.1の分析により示されました。タスク固有のモデルと比較すると、細かい分類や抽象的なタスクではCLIPの性能が劣ることが分かりました。今後の研究では、これらのタスクに対する性能向上が求められます。
論文の感想
本論文「Learning Transferable Visual Models From Natural Language Supervision」は、コンピュータビジョンと自然言語処理の分野における革新的なアプローチを紹介しています。以下に、この論文に対する感想を作成しました。
1. 革新的なアプローチ
CLIP(Contrastive Language-Image Pre-training)は、従来の視覚モデルとは異なり、自然言語による監督を利用して視覚表現を学習するという新しいアプローチを採用しています。このアプローチは、ラベル付きデータセットに依存せず、インターネットから収集された膨大な(画像、テキスト)ペアを活用することで、多様な視覚概念を学習できる点が非常に革新的です。
2. ゼロショット転移の高い性能
CLIPのゼロショット転移能力は、様々なデータセットで競争力のある結果を示しており、追加の訓練なしで新しいタスクに適応する能力が証明されています。これは、実際の応用において非常に有用であり、幅広いタスクへの迅速な対応が期待できます。
3. バイアスとデータ効率性の課題
一方で、CLIPはインターネットから収集されたデータに基づいているため、社会的なバイアスを学習する可能性があります。この点については、今後の研究での対策が必要です。また、CLIPは大量のデータを必要とするため、データ効率性の向上も今後の重要な課題とされています。
4. 今後の展望と可能性
本論文は、視覚モデルの学習における新しい可能性を示しており、自己監督学習の統合や新しいベンチマークの作成など、今後の研究方向についても具体的な提案がなされています。これにより、さらに高性能で汎用性のある視覚モデルの実現が期待されます。
結論
本論文は、自然言語監督を利用した視覚モデルの学習という新たな道を切り開くものであり、今後の研究や応用に多大な影響を与えることが予想されます。CLIPの提案手法とその成果は、コンピュータビジョンと自然言語処理の分野における重要な一歩と言えるでしょう。
参考文献
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever,”Learning Transferable Visual Models From Natural Language Supervision”,