この記事は次の論文を解説したものです。
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
“High-Resolution Image Synthesis with Latent Diffusion Models”,CVPR 2022

概要
論文の概要
高解像度画像生成の分野では、限られた計算リソースで効率的に高品質な画像を生成する手法が求められています。本論文では、その課題を解決するために「潜在拡散モデル(Latent Diffusion Models, LDMs)」を提案しています。この手法は、計算コストを削減しながら、生成過程を柔軟に制御できるという特徴を持っています。
論文の目的
この論文の目的は次の2点です:
- 高解像度画像生成において計算効率の高い手法を開発すること。
- 限られた計算資源で高品質な画像生成を実現すること。
提案された手法
提案された手法は以下のように実現されます
潜在空間での拡散モデルの訓練
拡散モデル(Diffusion Models, DMs)を事前に学習されたオートエンコーダの潜在空間で訓練することで、通常の画素空間での訓練に比べて計算コストを大幅に削減します。潜在空間での訓練により、効率的な学習が可能になります。
クロスアテンション層の導入
LDMにはクロスアテンション層が導入されており、テキストやバウンディングボックスなどの条件付き入力に柔軟に対応できます。これにより、生成される画像をさまざまな条件で制御することが可能です。
結果
LDMは以下のタスクで顕著な成果を挙げています:
- 画像修復(インペインティング)やクラス条件付き画像生成において最先端の性能を達成。
- テキストから画像への生成、無条件画像生成、超解像など多様なタスクにおいて高い競争力を示しました。
- 従来のピクセルベースの拡散モデルと比較して、計算資源の使用量を大幅に削減。
主な貢献
この研究の主な貢献は次の通りです:
多様なタスクへの適用 – 高解像度画像生成のための条件付けメカニズムを設計し、さまざまなタスクに応用可能であることを示しました。
計算効率と高品質な画像生成の両立 – 潜在空間での拡散モデルの訓練により、計算効率を向上させつつ、高品質な画像生成が可能になりました。
柔軟な条件付き入力への対応 – クロスアテンション層の導入により、テキストやバウンディングボックスなどの条件付き入力に柔軟に対応できました。
結論
LDMは、高解像度画像生成における計算効率と性能を大幅に向上させ、さまざまな条件付き画像生成タスクで優れた結果を示しました。潜在空間での拡散モデルの訓練は、計算コストを削減しつつ、高い視覚的忠実性を維持する効果的な方法であることが確認されています。
生成モデル同士の比較
概要
このセクションでは、画像生成に関連する既存の研究をレビューし、提案手法であるLDMの位置づけを明確にします。
生成モデル
GANs
GANsは高解像度画像を効率的に生成しますが、学習の不安定性や最適化の困難さが課題であり、特にモード崩壊が問題となります。
VAEs
VAEsはデータの潜在構造を捉えるのが得意ですが、生成される画像の品質はGANsに劣ります。
Flow-based Models
フローベースのモデルは確率密度変換でデータを生成しますが、サンプルの品質がGANsよりも低いです。
ARMs
ARMsは各ピクセルを順に生成するため、計算負荷が大きく、高解像度画像の生成に時間がかかります。
Diffusion Models (DMs)
DMsはクラス条件付き画像生成や超解像で優れた結果を示しますが、高次元のピクセル空間での計算コストが高いという課題があります。
二段階画像生成
VQ-VAEs
オートレグレッシブモデルを使用して、離散化された潜在空間の表現を学習し、テキストから画像の生成にも適用されます。
VQGANs
第1段階でオートエンコーダを使用し、第2段階でオートレグレッシブトランスフォーマーを用いて画像を生成します。
その他のアプローチ
条件付き可逆ネットワークを使用して、異なる領域の潜在空間間での転送を行います。
提案手法の位置づけ
本研究のLDMは、従来の拡散モデルにおける計算と推論コストの高さを解決するために、潜在空間での訓練を行います。これにより、計算効率を大幅に向上させ、高解像度画像生成の性能を維持しつつ、計算資源の消費を削減します。
潜在拡散モデルの手法
このセクションでは、提案するLatent Diffusion Models (LDMs)の手法について説明します。主な内容は以下の3つに分かれています。
潜在空間への変換
画像を低次元の潜在空間に効率的に変換し、重要な視覚情報を保持しつつ計算コストを削減することです。
VQ正則化: デコーダ内にベクトル量子化層を使用し、潜在表現を離散化します。
オートエンコーダの使用: 画像 を潜在表現 にエンコードし、デコーダ により再構成します。
ダウンサンプリング係数 の導入: 異なる圧縮率を実験し、最適なバランスを見つけます。
正則化手法:
KL正則化: 潜在空間の変動を抑制するために標準正規分布へのペナルティを課します。
VQ正則化: デコーダ内にベクトル量子化層を使用し、潜在表現を離散化します。
潜在拡散モデル(Latent Diffusion Models)
潜在拡散モデルの目的は、潜在空間で拡散モデルを訓練し、計算効率を向上させながら高品質な画像生成を実現することです。
- 生成モデリング: オートエンコーダ とデコーダ により画像を低次元の潜在空間に変換し、拡散モデルを訓練します。
- 拡散モデルの訓練: ノイズから始め、逐次的にノイズを除去するプロセスを学習します。
- 効率化: 潜在空間での拡散プロセスはピクセル空間に比べて次元が低く、計算コストを大幅に削減できます。
条件付けメカニズム
条件付けメカニズムの目的は、特定の入力(例:テキスト)に基づいた画像生成を可能にすることです。
- クロスアテンション機構: クロスアテンション層を使用し、異なる入力モダリティを統合します。
- 条件付けの実装: 条件付けオートエンコーダ で入力条件を中間表現に変換し、U-Netの中間層に結合します。
図の説明
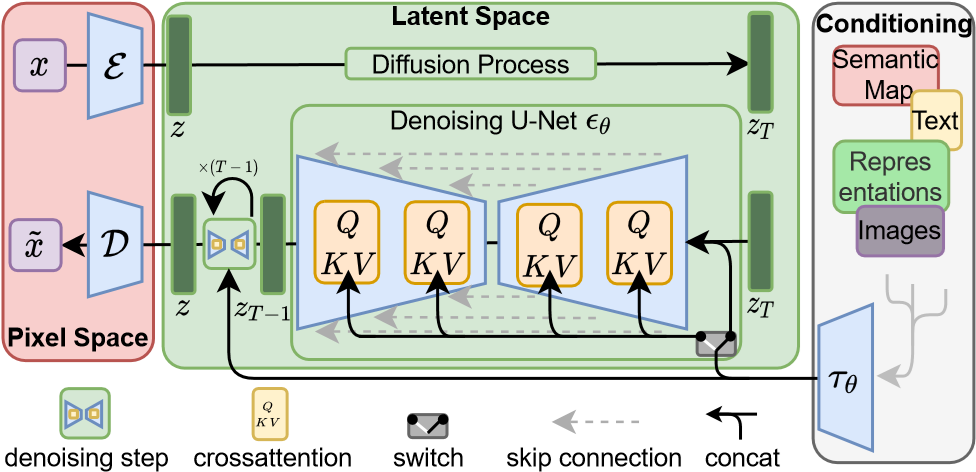
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer,”High-Resolution Image Synthesis with Latent Diffusion Models”, CVPR 2022, P4,Figure 3.
この図は、Latent Diffusion Models (LDMs) の基本的な動作原理を示しており、エンコード、拡散、デコードのプロセスがどのように連携して画像生成を行うかを説明しています。
ピクセル空間(Pixel Space)
- x: 元の画像データ。
- E (エンコーダ): ピクセル空間から潜在空間への変換を行い、画像 を潜在表現 にエンコードします。
- D (デコーダ): 潜在空間からピクセル空間への逆変換を行い、潜在表現 から再構成された画像 を生成します。
潜在空間(Latent Space)
- z: エンコードされた潜在表現。
- 拡散プロセス (Diffusion Process): ノイズを徐々に付加していくプロセスです。
- デノイジング U-Net εθ ノイズを徐々に除去し、クロスアテンション層で条件付き入力(例:テキスト、セマンティックマップ)を取り入れて潜在表現を更新します。
- Q, K, V: クエリ(Query)、キー(Key)、バリュー(Value)として使用され、条件付き生成を可能にします。
条件付け(Conditioning)
- (条件付けエンコーダ): テキストやセマンティックマップなどを潜在表現に変換し、生成プロセスに条件を付けます。
- 条件付き入力の種類:
- Semantic Map: 画像の意味的な情報。
- Text: 自然言語の条件付け情報。
- Representations: その他の潜在表現。
- Images: 条件付き生成のための参照画像。
- 条件付き入力の種類:
流れの説明
- エンコード: 元の画像 をエンコーダ によって潜在表現 にエンコードします。
- 拡散プロセス:
- 潜在空間でノイズが追加され、デノイジング デノイジング U-Net εθで条件付き入力を取り入れながらノイズを除去します。
- デコード: 最終的な潜在表現 をデコーダ によって再構成し、画像 を生成します。
結論
本セクションでは、LDMの設計、訓練方法、および条件付けメカニズムについて説明しました。LDMは、計算効率を向上させつつ、高品質な画像生成を実現し、異なる条件にも柔軟に対応できるモデルです。このアプローチにより、画像生成の柔軟性と精度が向上します。
実験結果
このセクションでは、提案するLatent Diffusion Models (LDMs) の性能を評価するための実験結果について説明します。以下の5つの実験を通じて、LDMsの優れたパフォーマンスを確認しました。
LDMs同士の性能分析
目的
異なるダウンサンプリング因子によるLDMsの性能を比較し、計算効率と画像品質のトレードオフを評価することです。
結果
LDM-4, LDM-8: 計算効率と品質のバランスが良く、最も優れた結果を示しました。
LDM-1, LDM-2: 訓練に時間がかかり効率が低い。
LDM-32: 情報損失が大きく、画像品質が低下。
潜在拡散を用いた画像生成
目的
様々なデータセットで無条件画像生成の性能を評価することです。
データセットと結果
結果: CelebA-HQで最先端のFIDスコアを達成し、他のデータセットでも競合手法と同等以上の性能を示しました。
データセット: CelebA-HQ, FFHQ, LSUN-Churches, LSUN-Bedrooms, ImageNet
条件付き潜在拡散
目的
テキストやレイアウト条件付き画像生成の性能を評価することです。
結果
レイアウト条件付き画像生成(OpenImages, COCO): 高品質な画像生成を実現しました。
テキスト条件付き画像生成(MS-COCO): ARモデルやGANと同等の性能を達成。
潜在拡散を用いた超解像
目的
低解像度画像を高解像度に変換する性能を評価します。
結果
PSNRとSSIM: ガイド付きモデルが最も高いスコアを示しました。
LDM-SR: 競合手法より優れたFIDスコアを達成。
潜在拡散を用いた画像修復
目的
画像の欠損部分を修復する性能を評価します。
結果
LDM-4: 大きな欠損部分の修復において、既存手法を超える高いFIDスコアを達成しました。
結論
実験結果から、LDMsは計算効率を大幅に向上させながらも高品質な画像生成を実現できることが確認されました。特に、異なる条件付きタスクに対しても柔軟に対応できる点が強調されています。
限界と社会的影響
このセクションでは、提案手法であるLatent Diffusion Models (LDMs) の限界と、その社会的影響について議論します。
限界
サンプリング速度
LDMsは計算効率を向上させていますが、依然としてGANsに比べてサンプリング速度が遅いという課題があります。これは逐次的なサンプリングプロセスに起因しています。
高精度タスクへの適用
LDMsは高品質な画像生成を実現していますが、ピクセルレベルでの高精度が要求されるタスクでは、潜在空間の再構成能力が制約となる場合があります。特に超解像モデルにおいて、細部の再現に限界があります。
潜在空間の制約
LDMsは潜在空間の選択と正則化に依存しており、KL正則化やVQ正則化の設定次第で生成品質が大きく変わる可能性があります。則化に依存します。KL正則化やVQ正則化の設定により生成品質が影響を受ける可能性があります。
社会的影響
創造的応用の促進
LDMsはアート生成やデザイン支援といった創造的応用へのアクセスを容易にし、多くのユーザーが高度な画像生成技術を利用できる環境を提供します。
偽造データのリスク
高品質な画像生成技術が普及することで、偽造データの作成・拡散リスクが高まります。特にディープフェイクは、情報操作やプライバシー侵害に悪用される可能性があります。
トレーニングデータのリーク
生成モデルはトレーニングデータのパターンを学習するため、元のデータセットの情報をリークするリスクがあります。センシティブな情報を含むデータセットに対して、このリスクは特に重大です。
バイアスの再現と拡大
生成モデルはトレーニングデータに存在するバイアスを再現し、拡大する可能性があります。人種や性別などに関するバイアスが含まれる場合、それらを持つ画像が生成されるリスクがあります。
結論
LDMsは高効率かつ高品質な画像生成を実現する一方で、いくつかの限界と社会的影響を持っています。生成データの悪用リスクやバイアスの拡散については慎重な検討と対策が必要です。今後も、生成モデルの倫理的な使用と開発に向けた研究と議論が求められます。
潜在拡散モデルの結論
概要
本研究では、Latent Diffusion Models (LDMs) を提案し、高解像度画像生成の効率と品質を向上させる方法を示しました。以下に研究の主要な結論と貢献をまとめます。
主な貢献
効率的な画像生成
LDMsは潜在空間での拡散モデルの訓練により、計算コストと推論コストを大幅に削減しました。高品質な画像生成を維持しつつ、計算資源を最小限に抑えることが可能です。
クロスアテンション条件付けメカニズム
クロスアテンション層により、テキストやセマンティックマップなどの多様な条件付き入力に対応した画像生成が可能となりました。この条件付けメカニズムは、多様なタスクに適用可能です。
多様なタスクへの適用
LDMsは画像インペインティング、クラス条件付き画像生成、テキスト条件付き画像生成、超解像など、さまざまなタスクにおいて高い性能を示しました。
研究の結論
LDMsは高解像度画像生成において、計算効率と生成品質を大幅に向上させました。潜在空間での拡散モデルの訓練により、従来のピクセルベースのモデルと比較して計算リソースを削減できます。また、クロスアテンション層により、柔軟な条件付き画像生成が可能となり、多様なタスクに対応する競争力のある手法となりました。
将来の研究方向
今後は拡散モデルのサンプリング速度の向上や、より高精度なタスクへの適用が必要です。また、生成モデルの倫理的使用や悪用防止に関する対策についても引き続き議論が求められます。
この論文のまとめ
Latent Diffusion Models (LDMs) は、高効率かつ高品質な画像生成を実現する有望な手法です。さらなる性能向上と新たな応用分野の開拓が期待されます。
高効率な画像生成の実現
LDMsは潜在空間での拡散プロセスを利用し、計算コストを大幅に削減しています。必要な計算資源を最小限に抑えつつ、高品質な画像生成を可能にするため、実用性が高いアプローチです。
クロスアテンション条件付けメカニズムの導入
クロスアテンション層により、多様な条件付き入力に柔軟に対応する画像生成が可能となりました。このメカニズムは多様なタスクに適用可能で、応用範囲を広げる点で有用です。
多様なタスクへの適用と高性能の実証
LDMsは画像インペインティング、クラス条件付き画像生成、テキスト条件付き画像生成、超解像など、多様なタスクにおいて高い性能を示しており、その汎用性と有用性が強調されています。
潜在的な限界と社会的影響
本研究にはいくつかの限界があります。サンプリング速度の遅さや、高精度が要求されるタスクにおける潜在空間の制約が課題として残されています。また、生成技術の社会的影響についても、偽造データの作成やデータリークのリスクがあり、慎重な対策が必要です。
将来の展望
LDMsは高効率で高品質な画像生成を実現する手法であり、今後さらなる性能向上が期待されます。特に、サンプリング速度の向上、精度の高いタスクへの適用、生成データの悪用防止に関する対策が求められます。
結論
総じて、Latent Diffusion Models (LDMs) は、高解像度画像生成の分野において重要な進展をもたらす手法です。本研究の成果は、計算効率と生成品質の両立を実現し、多様な条件付き入力に柔軟に対応できる点で非常に価値があります。今後の研究と応用の進展が非常に楽しみです。