
この記事は次の論文を紹介したものです。
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, “LoRA: Low-Rank Adaptation of Large Language Models”

この論文の概要
背景と課題
近年、自然言語処理(NLP)において、大規模な事前学習済み言語モデル(例えばGPT-3)が注目されています。これらのモデルは、一般的なドメインデータで事前に学習され、特定のタスクやドメインに適応させることで高い性能を発揮します。しかし、これらのモデルをすべてのパラメータを再トレーニングする完全な微調整は、特に巨大なモデルでは実現が難しく、計算資源とメモリ使用量の面で非現実的です。
提案手法:Low-Rank Adaptation(LoRA)
この課題に対し、Microsoftの研究チームはLow-Rank Adaptation(LoRA)という新しい手法を提案しました。LoRAは、事前学習されたモデルの重みを凍結し、トレーニング可能な低ランクの行列を各層に注入することで、必要なパラメータの数を大幅に削減します。これにより、計算資源の節約とメモリ使用量の削減が可能になります。
実験結果と利点
LoRAの有効性を評価するために、RoBERTa、DeBERTa、GPT-2、GPT-3などのモデルを用いて広範な実験が行われました。その結果、LoRAは従来の完全な微調整と同等かそれ以上の性能を発揮することが確認されました。特に以下の利点が強調されました:
- パラメータの削減: LoRAは、トレーニングパラメータの数を最大10,000分の1に削減します。
- メモリ効率: GPUメモリの使用量を3分の1に削減します。
- トレーニング速度の向上: トレーニング速度が向上し、計算資源の節約にも寄与します。
- 推論遅延なし: LoRAは追加の推論遅延を引き起こさないため、実運用環境での適用が容易です。
将来的な展望
LoRAは他のパラメータ効率の高い適応手法と組み合わせることで、さらなる性能向上が期待されます。また、LoRAの適応メカニズムの解明が進むことで、より高度な適応手法の開発が可能となります。さらに、現在は主にトランスフォーマーモデルに焦点を当てていますが、他のアーキテクチャや新しいドメインへの適用も今後の研究課題として重要です。
結論
LoRAは、大規模な事前学習済み言語モデルの効率的な適応手法として非常に有望です。計算資源とメモリ使用量を大幅に削減しながら、高い性能を維持することが可能であり、実運用環境での適用が容易です。LoRaは「基盤モデルの微調整」がコンセプトです。今後の研究により、さらに多くの適用範囲が広がり、NLPの分野での革新を促進することでしょう。
Abstract(概要)
LORA(Low-Rank Adaptation)は、巨大な事前学習済み言語モデル(例えばGPT-3)を効率的に特定のタスクに適応させるための新しい手法です。この手法は、モデルの全パラメータを再トレーニングする従来の完全な微調整の課題を解決するために開発されました。
背景と問題点
自然言語処理の分野では、一般的なドメインデータで大規模な事前学習を行い、その後特定のタスクやドメインにモデルを適応させることが重要です。しかし、モデルが大きくなるにつれて、すべてのパラメータを再トレーニングする完全な微調整は非現実的です。特に、GPT-3 175Bのような巨大なモデルでは、各タスクごとに独立した微調整済みモデルをデプロイするのは非常に高コストです。
LoRAの提案
LoRAは、事前学習されたモデルの重みを凍結し、トレーニング可能な低ランク分解行列をトランスフォーマーアーキテクチャの各層に注入することで、この課題を解決します。これにより、下流タスクに必要なトレーニングパラメータの数を大幅に削減し、効率的なモデル適応が可能になります。
メリットと実証
LoRAの主なメリットは次の通りです:
トレーニングパラメータの削減: GPT-3 175Bを例にすると、トレーニングパラメータの数を最大で10,000分の1に削減できます。
GPUメモリ要件の削減: GPUメモリの使用量を3分の1に削減できます。
高い性能: RoBERTa、DeBERTa、GPT-2、GPT-3などのモデルにおいて、LoRAは従来の完全な微調整と同等かそれ以上の性能を発揮します。
追加の推論遅延なし: LoRAは、アダプター層とは異なり、追加の推論遅延を引き起こしません。
さらに、LoRAは言語モデルの適応におけるランク不足の問題に関する実証的な調査を提供し、その効果を示しています。また、LoRAをPyTorchモデルと統合するためのパッケージと、RoBERTa、DeBERTa、GPT-2用の実装とモデルチェックポイントも公開されています。
結論
LORAは、大規模な事前学習済み言語モデルを効率的に適応させるための革新的な手法です。トレーニングパラメータの数を大幅に削減し、GPUメモリの要件を軽減しながら、高い性能を維持することができます。これにより、巨大なモデルの実運用が現実的となり、NLPの分野での新たな可能性が広がります。
Introduction(序論)
LoRA(Low-Rank Adaptation)は、大規模な事前学習済み言語モデルの適応に関する新しい手法です。この手法は、従来の完全な微調整が抱える課題を解決するために提案されました。
背景
近年、自然言語処理(NLP)の分野では、事前学習された大規模言語モデルの重要性が増しています。これらのモデルは、一般的なドメインデータで事前に学習され、その後、特定のタスクやドメインに適応されることで、高い性能を発揮します。例えば、GPT-3は1750億ものパラメータを持ち、広範なNLPタスクに対して非常に強力な能力を示しています。
完全な微調整の課題
しかし、これらの大規模モデルを完全に微調整することには大きな課題があります。完全な微調整とは、事前学習されたすべてのパラメータを再トレーニングするプロセスですが、モデルが大きくなるにつれて、これは計算資源とメモリの面で非常に高コストになります。具体的には、GPT-3のような巨大なモデルでは、各タスクごとに独立した微調整済みモデルを作成することは実質的に不可能です。
LoRAの提案
この課題を解決するために、Microsoftの研究チームはLoRA(Low-Rank Adaptation)を提案しました。LoRAの基本的なアイデアは、事前学習されたモデルの重みを凍結し、トランスフォーマーアーキテクチャの各層にトレーニング可能な低ランクの行列を注入することです。これにより、必要なトレーニングパラメータの数を大幅に削減しながら、高い性能を維持することができます。
LoRAの利点
LoRAにはいくつかの重要な利点があります:
トレーニングパラメータの削減: 事前学習されたモデルの重みを凍結することで、トレーニングパラメータの数を劇的に減少させます。
メモリ効率の向上: トレーニング時のメモリ使用量が大幅に削減され、より少ない計算資源でトレーニングが可能になります。
推論効率: LoRAは、推論時に追加の遅延を発生させないため、実運用環境での適用が容易です。
高い適応性能: LoRAは、従来の完全な微調整と同等かそれ以上の適応性能を示します。
結論
序論セクションでは、LoRAが提案された背景と、その手法がどのようにして完全な微調整の課題を解決するかについて説明しています。LoRAは、大規模な言語モデルを効率的に適応させるための革新的なアプローチであり、NLPの分野における新たな可能性を切り開くものです。
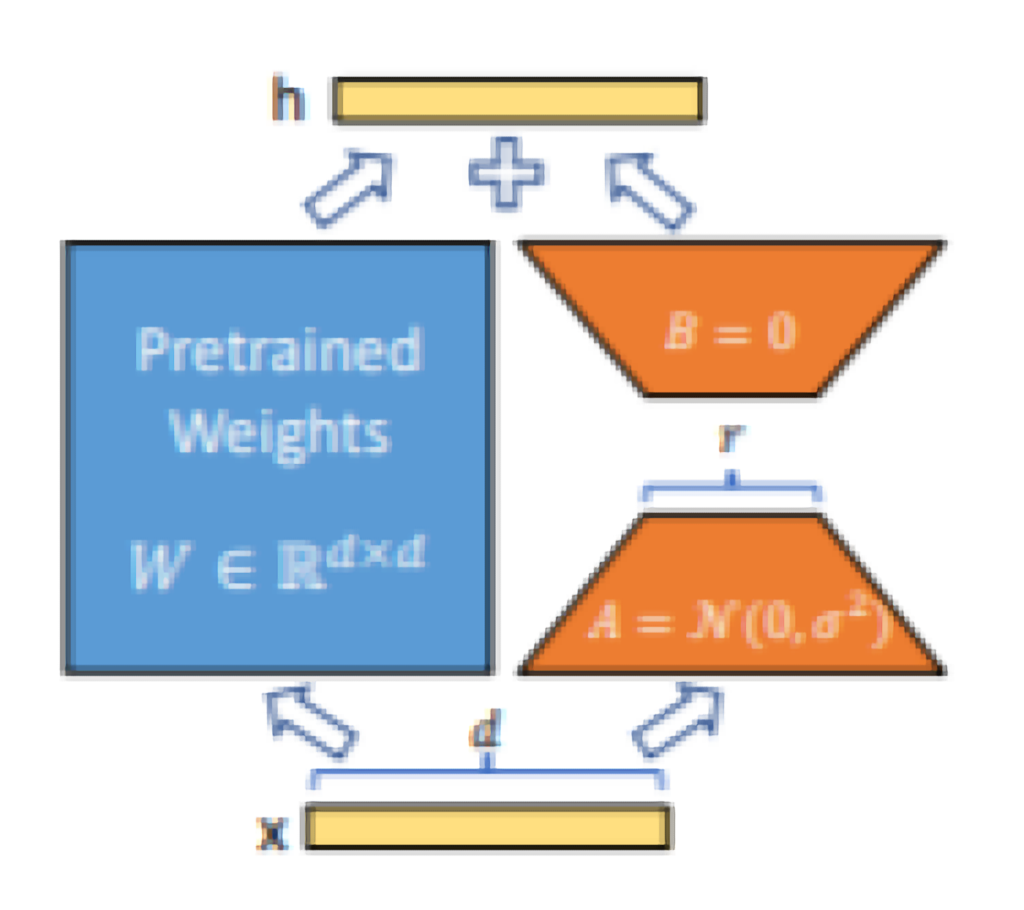
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, “LoRA: Low-Rank Adaptation of Large Language Models”,1P,Figure 1,
図の構成要素
- 事前学習済みの重み(Pretrained Weights)
- 左側の青いボックスには「Pretrained Weights」と書かれており、事前学習された重み行列 Wが示されています。この行列は、次元 d×dの大きさを持ちます。
- 入力ベクトル x
- 図の下部にある xは、入力ベクトルを表します。次元は dです。このベクトルがモデルに入力されます。
- 低ランク行列 A と B
- 右側のオレンジ色の三角形は低ランク行列 Aと Bを示しています。これらの行列は、LoRAの核となる要素です。
- A: 次元 r×dの行列で、初期化時に正規分布 N(0,σ2)に従ってランダムに設定されます。
- B: 次元 d×rの行列で、初期値はゼロです。
- 出力ベクトル h
- 図の上部にある hは、最終的な出力ベクトルを表します。このベクトルは、事前学習された重みと低ランク行列の積和によって得られます。
処理の流れ
- 入力ベクトルの処理
- 入力ベクトル xが事前学習された重み行列 Wを通過します。この処理は通常の線形変換です。
- 低ランク行列の適用
- 入力ベクトル xは、まず低ランク行列 Aを通過して変換されます。次に、変換された結果が低ランク行列 Bを通過します。この一連の処理によって、低ランクの次元 rを経由した新しい変換が得られます。
- 重みの更新
- 得られた変換結果は、事前学習された重み行列 Wの出力に加算されます。これにより、最終的な出力ベクトル hが得られます。
図のポイント
- 効率的な適応: LoRAは、事前学習された重みをそのまま使用し、追加の低ランク行列を導入することで、パラメータ数を劇的に減少させます。
- 柔軟な適用: 図からわかるように、LoRAは既存のモデルに対して容易に適用可能です。重み行列 Wの出力に対して低ランク行列の積和を加えるだけで、適応が実現されます。
Problem Statement(問題設定)
LoRA(Low-Rank Adaptation)の開発背景と、その提案手法が解決しようとしている具体的な課題について説明します。
1. 言語モデリングの目的
大規模な事前学習済み言語モデル(例えばGPT-3)は、一般的なドメインデータで事前学習され、特定のタスクに適応されることで高い性能を発揮します。これらのモデルを特定のタスク(例えばテキスト要約や質問応答)に適応させることが求められます。
2. 完全な微調整の課題
完全な微調整(Full Fine-Tuning)では、事前学習されたすべてのパラメータを再トレーニングします。以下の問題があります:
- 計算リソースの負担: GPT-3のような巨大なモデルでは、すべてのパラメータを再トレーニングするために膨大な計算リソースが必要です。
- メモリ使用量: 完全な微調整はメモリ使用量も増加させ、特にGPUメモリの制約が問題となります。
- 運用コスト: 各タスクごとに独立した微調整済みモデルを作成することは、保存とデプロイのコストが高くなります。
3. パラメータ効率の高い適応の必要性
下流タスクに対して効率的にモデルを適応させるためには、トレーニングするパラメータの数を減らすことが求められます。LoRAのアプローチは、パラメータ効率の高い適応手法を提供します。
4. LoRAの基本アイデア
LoRAの基本的な考え方は、事前学習されたモデルの重みを凍結し、更新部分を低ランク行列分解を通じて表現することです。
- 低ランク行列分解: 事前学習された重み行列 W に対して、更新部分 ΔWを BA として表現します。ここで、Bと Aは低ランクの行列です。
- トレーニングパラメータの削減: この手法により、更新に必要なパラメータの数が大幅に削減されます。
5. LoRAの適用方法
LoRAは、トランスフォーマーアーキテクチャの各層に適用されます。特に、自己注意モジュールのクエリ、キー、バリュー、出力の重み行列に対して低ランク分解行列を注入します。
まとめ
問題設定のセクションでは、従来の完全な微調整が抱える課題と、LoRAがどのようにこれらの課題を解決するかについて説明しています。LoRAは、事前学習されたモデルの重みを凍結し、低ランク分解を用いることで、トレーニングパラメータの数を大幅に削減し、計算リソースとメモリ使用量の効率化を実現します。これにより、より効率的かつ実用的なモデルの適応が可能になります。
Related Work(関連研究)
LoRA(Low-Rank Adaptation)の背景を理解するためには、関連する既存の研究を知ることが重要です。このセクションでは、言語モデルの適応、プロンプトエンジニアリング、パラメータ効率の高い適応手法、低ランク構造に関連する研究について説明します。
1. トランスフォーマー言語モデル(Transformer Language Models)
トランスフォーマーアーキテクチャは、自己注意機構を用いたシーケンス・トゥ・シーケンスモデルであり、自然言語処理において大きな成功を収めています。BERTやGPT-2などのモデルは、事前学習と微調整を通じて高い性能を示しています。しかし、これらのモデルを完全に微調整することは計算資源の面で非常に負担が大きく、特にGPT-3のような超大規模モデルではさらに困難です。
2. プロンプトエンジニアリングと微調整(Prompt Engineering and Fine-Tuning)
プロンプトエンジニアリングは、GPT-3のようなモデルを少量の追加トレーニング例を用いて適応させる技術です。しかし、この方法は入力プロンプトの設計に依存し、必ずしも最適な結果を得られるわけではありません。一方、完全な微調整は全パラメータを再トレーニングしますが、巨大なモデルでは非現実的です。これらの背景から、より効率的なパラメータ適応手法が求められています。
3. パラメータ効率の高い適応手法(Parameter-Efficient Adaptation)
パラメータ効率の高い適応手法として、アダプター層が提案されています。この手法では、既存の層の間に新しい層を挿入し、トレーニングするパラメータの数を減らします。しかし、アダプター層は追加の推論遅延を引き起こします。また、入力単語埋め込みの最適化や連続プロンプトの最適化などの手法もありますが、これらはシーケンス長の減少を引き起こす可能性があります。
4. 深層学習における低ランク構造(Low-Rank Structures in Deep Learning)
多くの機械学習問題には低ランク構造が内在しています。過剰にパラメータ化されたニューラルネットワークは、トレーニング後に低ランクの特性を示すことが知られています。LoRAは、この低ランク構造を利用し、ニューラルネットワークの適応を効率的に行う新しいアプローチです。これにより、計算とメモリの効率が向上し、適応タスクにおいて高い性能を発揮します。
まとめ
関連研究のセクションでは、LoRAがどのような背景と文脈で位置づけられるかを説明しています。特に、トランスフォーマー言語モデル、プロンプトエンジニアリング、パラメータ効率の高い適応手法、低ランク構造に関連する既存の研究が紹介されています。LoRAは、これらの研究を踏まえて、新たな適応手法として提案されており、その革新性が強調されています。
Method(手法)
LoRA(Low-Rank Adaptation)の手法セクションでは、この新しい適応手法の詳細な設計と実装について説明しています。LoRAの基本的なアイデア、具体的な設計、適用方法、そして実際の利点と制限について理解することができます。
1. 低ランクパラメータ化更新行列(Low-Rank-Parameterized Update Matrices)
LoRAの中心となるアイデアは、事前学習されたモデルの重みを凍結し、その上にトレーニング可能な低ランク行列を追加することです。これにより、下流タスクに必要なトレーニングパラメータの数が大幅に削減されます。
- 基本アイデア: LoRAは、事前学習された重み行列 Wの更新を低ランク行列の積 ΔW=BAで表現します。ここで、Bは d×rの行列、Aは r×kの行列であり、rは低ランクの次元です。
- トレーニング方法: 事前学習された重み Wは凍結され、トレーニング可能なパラメータは Bと Aのみです。これにより、計算とメモリの効率が向上します。
2. 追加の推論遅延なし(No Additional Inference Latency)
LoRAは、推論時に追加の遅延を引き起こさないように設計されています。これにより、実運用環境での適用が容易になります。
- 推論時の効率性: LoRAは、トレーニングが完了した後に事前学習済みの重み Wに低ランク行列 BAを加算し、W+BAとして保存します。これにより、推論時に追加の計算が不要となります。
- タスクの切り替え: 異なるタスクに対しては、新しい低ランク行列 Bと Aを適用するだけで済むため、メモリのオーバーヘッドが非常に小さくなります。
3. トランスフォーマーへのLoRAの適用(Applying LoRA to Transformer)
LoRAは、トランスフォーマーアーキテクチャの自己注意モジュールに適用されます。実験では、主にクエリとバリューの投影行列にLoRAを適用しました。
- 適用対象: LoRAは、トランスフォーマーの自己注意モジュール(例:クエリ、キー、バリュー、出力の重み行列)に適用されます。
- トレーニングの簡略化: トレーニングの簡略化とパラメータ効率の向上のため、自己注意モジュールの重みのみにLoRAを適用し、MLPモジュールの重みは凍結します。
4. 実際の利点と制限(Practical Benefits and Limitations)
LoRAの実際の利点と制限についても説明されています。
- 利点:
- メモリとストレージの削減: トレーニング時のVRAM使用量を最大2/3削減できます。
- トレーニングスピードの向上: 微調整と比較して、トレーニングのスループットが25%向上します。
- タスクの切り替えの効率化: タスクを切り替える際のコストが大幅に削減されます。
- 制限:
- バッチ処理の制約: 複数のタスクに対して異なる AAA と BBB を一度にバッチ処理するのは難しいです。ただし、推論時にレイテンシが重要でない場合は、動的にLoRAモジュールを選択することで対応できます。
まとめ
手法のセクションでは、LoRAの設計と実装の詳細が説明されています。LoRAは、事前学習された重みを凍結し、低ランク行列を導入することで、計算効率とメモリ効率を大幅に向上させます。また、追加の推論遅延を発生させないため、実際のアプリケーションにおいても非常に有用です。LoRAは、トランスフォーマーアーキテクチャに容易に適用でき、その利点と制限についても明確に説明されています。
Experiments(実験)
LoRA(Low-Rank Adaptation)の効果を評価するために、さまざまな実験が行われました。このセクションでは、使用したモデルとデータセット、実験の設定、そして得られた結果について詳しく説明します。
1. 実験の目的
実験の主な目的は、LoRAが従来の完全な微調整と比較してどの程度効果的であるかを評価することです。特に、以下の点について評価が行われました:
- モデルの品質
- トレーニングパラメータの数
- トレーニングスループット
- GPUメモリ使用量
2. 使用したモデルとデータセット
- モデル: 実験では、RoBERTa、DeBERTa、GPT-2、GPT-3などの事前学習済みモデルが使用されました。
- データセット: 自然言語理解(NLU)と自然言語生成(NLG)のタスクに対応する複数のデータセット(例:GLUE、WikiSQL、SAMSumなど)が使用されました。
3. 実験結果
- RoBERTaとDeBERTaの結果:
- GLUEベンチマークで評価した結果、LoRAは完全な微調整と同等かそれ以上の性能を示しました。
- メモリ使用量とトレーニング時間の削減が顕著で、実用的な利点が確認されました。
- GPT-2の結果:
- E2E NLG ChallengeなどのNLGタスクで評価した結果、LoRAは他の適応手法と比較しても優れた性能を発揮しました。
- 特に、低ランク設定でも高い効果が確認されました。
- GPT-3の結果:
- WikiSQLやMultiNLIなどの大規模タスクで評価した結果、LoRAは完全な微調整と同等またはそれ以上の性能を発揮しました。
- メモリ使用量の大幅な削減と、トレーニング速度の向上が確認されました。
4. 比較対象
実験では、LoRAの性能を以下の手法と比較しました:
- 完全な微調整(Full Fine-Tuning, FT): すべてのパラメータを再トレーニングする従来の手法。
- アダプター層(Adapter): パラメータ効率の高い適応手法の一つで、層の間に新しい層を追加する手法。
- ビットフィット(BitFit): バイアスベクトルのみをトレーニングする手法。
- プレフィックス・チューニング(Prefix Tuning): 入力トークンの前に特別なトークンを挿入して適応させる手法。
5. 考察
- 低ランク設定の有効性: LoRAは低ランク設定でも高い性能を維持し、パラメータの効率的な利用が可能であることが示されました。
- 実用性: LoRAは、トレーニングと推論の両方で計算資源の削減に寄与し、実際のアプリケーションでの適用可能性が高いことが確認されました。
まとめ
LoRAの実験セクションでは、提案手法の有効性を示すために広範な評価が行われました。LoRAは、従来の微調整手法と比較して、計算効率、メモリ効率、性能の面で優れていることが確認されました。特に大規模モデルでの適用が効果的であり、実運用においても非常に有用であることが実証されました。
Discussion(考察)
1. 実験結果の総評
LoRAは従来の完全な微調整や他のパラメータ効率の高い適応手法と比較して優れた性能を示しました。特に、以下の点でLoRAの優位性が確認されました:
- パラメータの削減: 大規模モデルのトレーニングパラメータを大幅に削減しながら、高い性能を維持できること。
- メモリ効率: GPUメモリの使用量を削減し、より少ないリソースで効率的にトレーニングを行えること。
- 推論効率: 追加の推論遅延を引き起こさず、実運用環境での適用が容易であること。
2. メリットの詳細
- トレーニング効率の向上: LoRAはトレーニング可能なパラメータの数を削減することで、トレーニング速度を向上させ、計算資源の節約にも寄与します。
- メモリ効率: トレーニング時のメモリ使用量が大幅に削減されるため、より少ないハードウェアリソースでトレーニングが可能になります。
- タスクの切り替えの柔軟性: LoRAは、異なるタスクに対する適応時にメモリのオーバーヘッドが非常に小さく、タスクの切り替えが迅速かつ効率的に行えます。
3. LoRAの限界
- 低ランク制約: LoRAは低ランクの行列分解に依存しており、一部の複雑なタスクにおいては、十分な表現力を持たない可能性があります。そのため、タスクに応じて適切なランクを選定する必要があります。
- バッチ処理の制約: 複数のタスクを同時にバッチ処理する際に、異なるLoRAモジュールを適用することは難しいため、特定のシナリオでは制約が生じる可能性があります。
4. 将来的な研究の方向性
- 他の手法との統合: LoRAは他のパラメータ効率の高い適応手法(例:プロンプトチューニングやアダプター層)と組み合わせることで、さらなる性能向上が期待されます。
- 適応のメカニズムの解明: LoRAの効果的な適応メカニズムを解明することで、適応の理論的理解が深まり、より高度な手法の開発が可能となります。
- 新しいアーキテクチャへの適用: 現在は主にトランスフォーマーモデルに焦点を当てていますが、他のアーキテクチャや新しいドメインへの適用も今後の研究課題として重要です。
まとめ
考察セクションでは、LoRAの実験結果を総括し、その有効性と利点について議論しています。また、LoRAの限界についても触れ、将来的な研究の方向性として他の適応手法との統合や適応メカニズムの解明、適用範囲の拡大が提案されています。このセクションは、LoRAの現状の評価と今後の研究の道筋を示す重要な部分です。
この論文のまとめ
LoRA(Low-Rank Adaptation)は、大規模な事前学習済み言語モデルを効率的に特定のタスクに適応させるための革新的な手法です。この論文解説記事を通じて、LoRAの背景、提案手法、実験結果、考察、結論について詳しく見てきました。
背景と課題: 完全な微調整が抱える計算資源とメモリ使用量の問題を解決するため、LoRAは提案されました。
提案手法: 事前学習されたモデルの重みを凍結し、低ランクの行列を導入することで、必要なトレーニングパラメータを大幅に削減するアプローチです。
実験結果: LoRAはRoBERTa、DeBERTa、GPT-2、GPT-3などのモデルで高い性能を発揮し、従来の完全な微調整と同等かそれ以上の結果を示しました。
考察: LoRAのメリットと限界について議論し、将来的な研究の方向性として他の適応手法との統合や適応メカニズムの解明、新しいアーキテクチャへの適用が提案されました。
結論: LoRAは計算資源とメモリの効率化を実現しながら、高い性能を維持することができるため、実運用においても非常に有用です。
LoRAは、自然言語処理における大規模モデルの適応に新しい視点を提供する重要な研究です。従来の手法が抱えていたリソースの問題を低ランク分解というシンプルで効果的な方法で解決する点が非常に印象的です。実験結果からも、その有効性が十分に実証されており、今後の研究や実用化が非常に期待されます。
特に、GPT-3のような超大規模モデルに対しても適用可能であり、トレーニングパラメータの数やメモリ使用量を劇的に削減できる点は、実務においても大きなメリットとなるでしょう。また、LoRAの柔軟性と効率性により、さまざまなタスクやドメインへの適応が容易になるため、NLPの応用範囲がさらに広がることが予想されます。
LoRAの今後の発展により、より多くの研究者や開発者がこの手法を活用し、大規模言語モデルの適応技術がさらに進化することを楽しみにしています。LoRAがNLPの分野における新たなスタンダードとなることを感じさせる素晴らしい研究でした。